Fingerprint Authentication¶
This tutorial demonstrates how to use a machine learning model to generate a unique signature from a grayscale image of a fingerprint. The generated signature can then be compared against previously generated signatures stored in flash memory to authenticate users.
Demo Video¶
The following is a video of the demo described in this tutorial:
Quick Links¶
GitHub Source - View this tutorial on Github
Run on Colab - Run this tutorial on Google Colab
C++ Example Application - View this tutorial’s associated C++ example application
Machine Learning Model - View this tutorial’s associated machine learning model
Overview¶
Objectives¶
After completing this tutorial, you will have:
A better understanding of how machine learning may be used to generate unique signatures
The tools needed to create a fingerprint dataset
All of the tools needed to develop your own signature generation machine learning model
A working demo to authenticate fingerprints
Content¶
This tutorial is divided into the following sections:
Running this tutorial from a notebook¶
For documentation purposes, this tutorial was designed to run within a Jupyter Notebook. The notebook can either run locally on your PC or on a remote server like Google Colab.
Refer to the Notebook Examples Guide for more details
Click here:
 to run this tutorial interactively in your browser
to run this tutorial interactively in your browser
NOTE: Some of the following sections require this tutorial to be running locally with a supported embedded platform connected.
Running this tutorial from the command-line¶
While this tutorial uses a Jupyter Notebook, the recommended approach is to use your favorite text editor and standard command terminal, no Jupyter Notebook required.
See the Standard Python Package Installation guide for more details on how to enable the mltk command in your local terminal.
In this mode, when you encounter a !mltk command in this tutorial, the command should actually run in your local terminal (excluding the !)
Required Hardware¶
Some parts of the tutorial requires a supported development board and the R503 Fingerprint Module.
See the Hardware Setup section of the Fingerprint Authenticator C++ application for details on how to connect the fingerprint module to the development board.
NOTE: Only the fingerprint module needs to be connected to the development board. You do not need to build the C++ application from source for this tutorial.
Install MLTK Python Package¶
Before using the MLTK, it must first be installed.
See the Installation Guide for more details.
!pip install --upgrade silabs-mltk
All MLTK modeling operations are accessible via the mltk command.
Run the command mltk --help to ensure it is working.
NOTE: The exclamation point ! tells the Notebook to run a shell command, it is not required in a standard terminal
!mltk --help
Usage: mltk [OPTIONS] COMMAND [ARGS]...
Silicon Labs Machine Learning Toolkit
This is a Python package with command-line utilities and scripts to aid the
development of machine learning models for Silicon Lab's embedded platforms.
Options:
--version Display the version of this mltk package and
exit
--install-completion [bash|zsh|fish|powershell|pwsh]
Install completion for the specified shell.
--show-completion [bash|zsh|fish|powershell|pwsh]
Show completion for the specified shell, to
copy it or customize the installation.
--help Show this message and exit.
Commands:
build MLTK build commands
classify_audio Classify keywords/events detected in a...
classify_image Classify images detected by a camera...
commander Silab's Commander Utility
compile Compile a model for the specified...
custom Custom Model Operations
evaluate Evaluate a trained ML model
fingerprint_reader View/save fingerprints captured by the...
profile Profile a model
quantize Quantize a model into a .tflite file
run_model_profiler_benchmarks Build and run the model profiler...
summarize Generate a summary of a model
train Train an ML model
tse_compress Perform compression of all weights in a...
update_params Update the parameters of a previously...
utest Run the all unit tests
view View an interactive graph of the given...
view_audio View the spectrograms generated by the...
Signature Generation Machine Learning Model Overview¶
Before continuing with this tutorial, it is recommended to review the MLTK Overview, which provides an overview of the core concepts used by the this tutorial.
While classification (e.g. predicting if an image contains a cat, dog, or goat) is a common usecase for embedded machine learning, another useful application of machine learning is signature generation. For example, given a grayscale image of someone’s fingerprint, generate a sequence of numbers that are unique to the fingerprint; different images of the same fingerprint should generate a nearly identical sequence of numbers while a different person’s fingerprint should generate a different sequence of numbers. The sequence of numbers is called the signature and machine learning is used to create the signature generator. Two signatures are considered similar if their euclidean distance is below a certain threshold.
This is illustrated as follows:
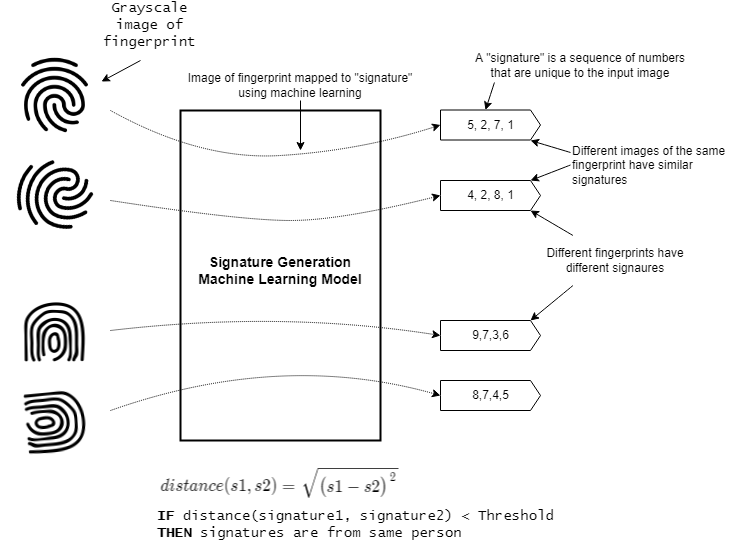
NOTE: While this tutorial uses grayscale images of fingerprints, many other sample types (audio, accelerometer, etc.) could theoretically be used as well.
Siamese Networks¶
The Siamese Network machine learning model architecture is used to generate the signatures.
Siamese Networks are neural networks which share weights between two or more sister networks, each producing embedding vectors of its respective inputs. In supervised similarity learning, the networks are then trained to maximize the contrast (distance) between embeddings of inputs of different classes, while minimizing the distance between embeddings of similar classes, resulting in embedding spaces that reflect the class segmentation of the training inputs. [1]
A siamese network can be illustrated as follows:
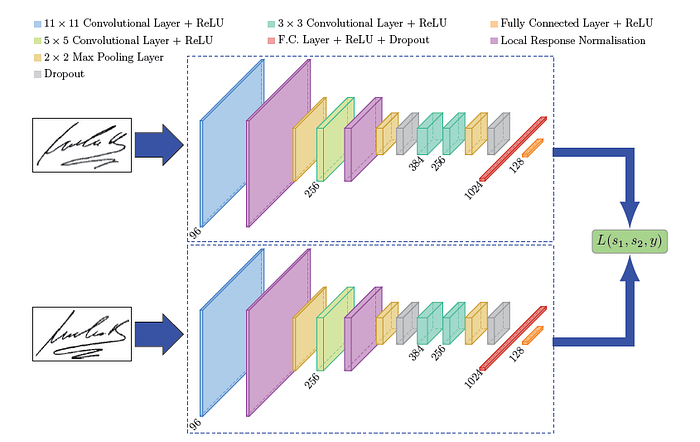
Siamese network used in Signet
There are several things to note about this diagram:
The top and bottom blocks of the diagram share the same weights and parameters
The top and bottom blocks are called a “tower” (so the model has two towers)
Only one of the towers is needed to generate the signature
The last layer of the tower is a fully connected layer, the output of this layer is the signature generated from the model input
The number of units (aka neurons) in the last fully connected layer determines the since of the generated signature
Refer to the following links for additional information about siamese networks:
Creating the dataset¶
Before training the model, a dataset is required. The dataset should be a collection of fingerprint images captured by the R503 Fingerprint Module.
NOTE: Due to privacy concerns, no dataset is provided by this tutorial. You must generate your own dataset using the instructions below.
Recall that the goal of ML model is to generate a sequence of numbers that are similar for the images of the same fingerprint and different for different fingerprints. Thus, the dataset should have many images of the same fingerprint.
The structure of the dataset might look something like:
abs/left/index/1.jpg - Person "abc", left hand, index finger, image 1
abs/left/index/2.jpg - Person "abc", left hand, index finger, image 2
abs/left/index/3.jpg - Person "abc", left hand, index finger, image 3
...
abs/left/thumb/1.jpg - Person "abc", left hand, thumb, image 1
abs/left/thumb/2.jpg - Person "abc", left hand, thumb, image 2
abs/left/thumb/3.jpg - Person "abc", left hand, thumb, image 3
...
The goal is to have has many different people and fingerprints as possible. However, it is critical that there are multiple images of the same fingerprint. This way, the ML model can learn the features that make fingerprints similar and different.
Generating the dataset¶
To aid the generation of the dataset, the MLTK provides the command:
mltk fingerprint_reader <model> --generate-dataset
NOTE: To use this command, you must have a locally connected development board with the R503 fingerprint module connected.
Refer to Hardware Setup for more details.
With the hardware setup, issue the command:
mltk fingerprint_reader fingerprint_signature_generator --generate-dataset
This will guide you through the process of capturing your fingerprints and saving them to your local PC. After the command completes, repeat the command with as many other peoples’ fingers as possible. The larger your dataset, the better your trained model will perform.
NOTE: The command above uses the pre-built model fingerprint_signature_generator. This argument is effectively ignored when using the --generate-dataset option.
WARNING: Be sure to backup your dataset directory after adding new samples!
Data preprocessing¶
The R503 Fingerprint Module generates 192x192 grayscale images.
Additional preprocessing is applied to the raw images to help the ML model learn the important features of the images.
The preprocessing algorithm source may be found in fingerprint_signature_generator_dataset.py
The following algorithms are used:
Color space balancing - This uses simple statistical centering and removes outliers
Sharpening - This applies 2D convolution using a harpening filter:
original + (original ? blurred) × amountQuality rejection - Using simple heuristics, if the image is found to be too blurry it is dropped
NOTE: These algorithms are used to preprocess the training dataset and on the embedded device at runtime (see data_preprocessor.cc)
Generating fingerprint pairs¶
To train a Siamese Network, pairs of fingerprint images are supplied as inputs to the model.
The image pairs are grouped into two classes:
match - Images are of the same fingerprint
no-match - Images are of different fingerprints
The fingerprint_signature_generator_dataset.py script is used to generate the image pairs from the fingerprint dataset.
Creating the Model¶
The model specification used by this tutorial may be found on Github: fingerprint_signature_generator.py.
Dataset¶
Due to privacy concerns, no dataset is provided by this tutorial. You must generate your own dataset using the instructions in this tutorial.
Once the dataset is generated, update the model specification script:
# NOTE: For privacy purposes, no dataset is provided for this model.
# As such, you must generate your own dataset to train this model.
# Refer to this model's corresponding tutorial for how to generate the dataset.
DATASET_ARCHIVE_URL = 'your-fingerprint-dataset-directory-or-download-url'
#DATASET_ARCHIVE_URL = '~/.mltk/fingerprint_reader/dataset'
And modify DATASET_ARCHIVE_URL point to your dataset directory or download URL.
Loss Function¶
As per the Keras tutorial: Image similarity estimation using a Siamese Network with a contrastive loss, a contrastive loss function is used for model training.
The source code for the custom loss function may be found on Github: mltk/core/keras/losses.py
The basic formula for contrastive loss is:
Contrastive loss = mean( (1-true_value) * square(prediction) + true_value * square( max(margin-prediction, 0) ))
Where margin defines the baseline for distance for which pairs should be classified as dissimilar.
Model Parameters¶
Recall that any preprocessing that is done to the data at training time must also be done at runtime on the embedded device. So, the exact parameters and algorithms used for color balancing and image sharpening must also be used on the embedded device.
To aid with this, the MLTK allows for embedding model parameters into the generated .tflite model file that is programmed onto the embedded device.
These parameters are set by the model python script, e.g.:
# The maximum "distance" between two signature vectors to be considered
# the same fingerprint
# Refer to the <model log dir>/eval/h5/threshold_vs_accuracy.png
# to get an idea of what this valid should be
my_model.model_parameters['threshold'] = 0.22
# Also add the preprocessing settings to the model parameters
preprocess_params = my_model.dataset.preprocess_params
my_model.model_parameters['sharpen_filter'] = my_model.dataset.sharpen_filter.flatten().tobytes()
my_model.model_parameters['sharpen_filter_width'] = my_model.dataset.sharpen_filter.shape[1]
my_model.model_parameters['sharpen_filter_height'] = my_model.dataset.sharpen_filter.shape[0]
my_model.model_parameters['sharpen_gain'] = my_model.dataset.sharpen_gain
my_model.model_parameters['balance_threshold_max'] = preprocess_params['balance_threshold_max']
my_model.model_parameters['balance_threshold_min'] = preprocess_params['balance_threshold_min']
my_model.model_parameters['border'] = preprocess_params['border']
my_model.model_parameters['verify_imin'] = preprocess_params['verify_imin']
my_model.model_parameters['verify_imax'] = preprocess_params['verify_imax']
my_model.model_parameters['verify_full_threshold'] = preprocess_params['verify_full_threshold']
my_model.model_parameters['verify_center_threshold'] = preprocess_params['verify_center_threshold']
And then read by the firmware application at runtime: data_preprocessor.cc
Saving the model¶
The trained Siamese network contains two “towers”, however, only one of the towers is required to generate the signature.
Thus, after model training, but before the model is saved, the model is modified so that only one of the towers is saved.
This is done using the on_save_keras_model TrainMixin property.
def my_keras_model_saver(
mltk_model:MyModel,
keras_model:KerasModel,
logger:logging.Logger
) -> KerasModel:
"""This is invoked after training successfully completes
Here want to just save one of the "towers"
as that is what is used to generate the fingerprint signature
on the device
"""
# The given keras_model contains the full siamese network
# Save it to the model's log dir
h5_path = mltk_model.h5_log_dir_path
siamese_network_h5_path = h5_path[:-len('.h5')] + '.siamese.h5'
logger.debug(f'Saving {siamese_network_h5_path}')
keras_model.save(siamese_network_h5_path, save_format='tf')
# Extract the embedding network from the siamese network
embedding_network = None
for layer in keras_model.layers:
if layer.name == 'model':
embedding_network = layer
break
if embedding_network is None:
raise RuntimeError('Failed to find embedding model in siamese network model, does the embedding model have the name "model" ?')
# Save the tower as the .h5 model file for this model
logger.debug(f'Saving {h5_path}')
embedding_network.save(h5_path, save_format='tf')
# Return the keras model
return embedding_network
my_model.on_save_keras_model = my_keras_model_saver
Train the model¶
With the dataset and model specification script ready, it’s time to train the model.
This can be done with the command:
mltk train fingerprint_signature_generator
NOTE: Replace fingerprint_signature_generator with the name of your model.
Evaluating the model¶
After training completes, the model is automatically evaluated. This is done using a custom evaluation function:
def my_model_evaluator(
mltk_model:MyModel,
built_model:Union[KerasModel, TfliteModel],
eval_dir:str,
logger:logging.Logger,
show:bool
) -> EvaluationResults:
"""Custom callback to evaluate the trained model
The model is effectively a classifier, but we need to do
a special step to compare the signatures in the dataset.
"""
results = ClassifierEvaluationResults(
name=mltk_model.name,
classes=mltk_model.classes
)
threshold = my_model.model_parameters['threshold']
logger.error(f'Using model threshold: {threshold}')
y_pred, y_label, y_dis = generate_predictions(
mltk_model,
built_model,
threshold
)
results.calculate(
y=y_label,
y_pred=y_pred,
)
results.generate_plots(
logger=logger,
output_dir=eval_dir,
show=show
)
match_dis = []
nomatch_dis = []
for y, dis in zip(y_label, y_dis):
if y == 0:
match_dis.append(dis)
else:
nomatch_dis.append(dis)
match_dis = sorted(match_dis)
match_dis_x = [i for i in range(len(match_dis))]
nomatch_dis = sorted(nomatch_dis)
nomatch_dis_x = [i for i in range(len(nomatch_dis))]
step = (match_dis[-1] - match_dis[0]) / 100
thresholds = np.arange(match_dis[0], match_dis[-1], step)
match_acc = []
nomatch_acc = []
for thres in thresholds:
valid_count = sum(x < thres for x in match_dis)
match_acc.append(valid_count / len(match_dis))
valid_count = sum(x > thres for x in nomatch_dis)
nomatch_acc.append(valid_count / len(nomatch_dis))
fig = plt.figure('Threshold vs Accuracy')
plt.plot(match_acc, thresholds, label='Match')
plt.plot(nomatch_acc, thresholds, label='Non-match')
#plt.ylim([0.0, 0.01])
plt.legend(loc="lower right")
plt.xlabel('Accuracy')
plt.ylabel('Threshold')
plt.title('Threshold vs Accuracy')
plt.grid(which='major')
if eval_dir:
output_path = f'{eval_dir}/threshold_vs_accuracy.png'
plt.savefig(output_path)
logger.info(f'Generated {output_path}')
if show:
plt.show(block=False)
else:
fig.clear()
plt.close(fig)
fig = plt.figure('Euclidean Distance')
plt.plot(match_dis_x, match_dis, label='Match')
plt.plot(nomatch_dis_x, nomatch_dis, label='Non-match')
plt.legend(loc="lower right")
plt.xlabel('Index')
plt.ylabel('Distance')
plt.title('Euclidean Distance')
plt.grid(which='major')
if eval_dir:
output_path = f'{eval_dir}/eclidean_distance.png'
plt.savefig(output_path)
logger.info(f'Generated {output_path}')
if show:
plt.show(block=False)
else:
fig.clear()
plt.close(fig)
return results
my_model.eval_custom_function = my_model_evaluator
This uses the model’s validation dataset to generate pairs of matching and non-matching fingerprint images. Each image from the pair is given to the trained model (recall that only one “tower” of the Siamese network is saved, thus the model only has one input) and its corresponding signature is generated.
The euclidean distance is then calculated between the two signatures. If the distances is less than a threshold (which is specified in the model parameters) then the two images are considered a match, otherwise they are considered a non-match.
The model predictions are then compared against the actual values to generate the various classification evaluation metrics.
Determining the threshold¶
The model threshold parameter must be determined before we can deploy this model. The model threshold is effectively the maximum euclidean distance between two signatures for them to be considered the same. e.g.:
IF distance(signature1, signature2) < threshold THEN
Signatures are from the same fingers
ELSE
Signatures are from different fingers
The MLTK evaluation scripts allow for determining this value.
After the evaluation completes, various diagrams are generated in the model’s log directory (the actual directory path is printed to the console, e.g.: ~/.mltk/models/fingerprint_signature_generator/eval/h5/).
One such diagram is:
from IPython.display import Image
from mltk.utils.path import fullpath
Image(filename=fullpath('~/.mltk/models/fingerprint_signature_generator/eval/h5/threshold_vs_accuracy.png'))
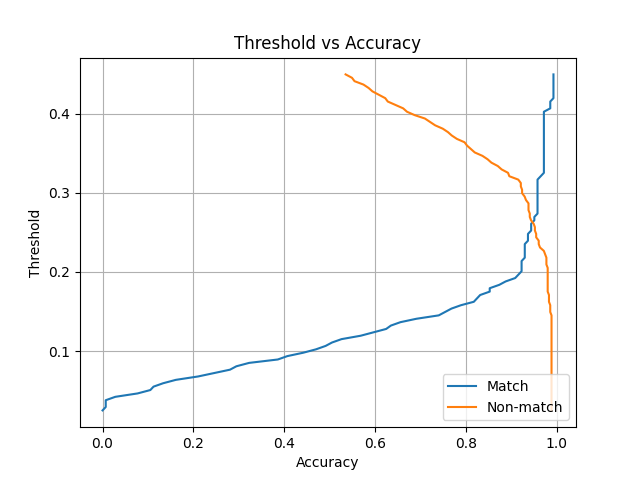
This diagram compares the threshold versus the model’s accuracy for each class.
NOTE: Different diagrams will be generated for different fingerprint datasets and model parameters.
So, from the diagram, if the threshold was set to 0.2, then the model would:
Correctly identify two matching fingerprints about 91% of the time
Correctly identify two non-matching fingerprints about 97% of the time
If the threshold was set to 0.1, then the model would:
Correctly identify two matching fingerprints about 45% of the time
Correctly identify two non-matching fingerprints about 98% of the time
Since the intent of this application is to authenticate users, we want the non-match accuracy to be as high as possible, while at the same time have a reasonably high match accuracy:
Non-match accuracy - The higher this is, the better the application rejects hackers from spoofing fingerprints
Match accuracy - The higher this is, the better the user-experience when using the application
The threshold value is set in the model specification python script, e.g.:
# The maximum "distance" between two signature vectors to be considered
# the same fingerprint
# Refer to the <model log dir>/eval/h5/threshold_vs_accuracy.png
# to get an idea of what this valid should be
my_model.model_parameters['threshold'] = 0.22
After updating the threshold, re-run the model evaluation with the command:
mltk evaluate fingerprint_signature_generator
Name: fingerprint_signature_generator
Model Type: classification
Overall accuracy: 95.469%
Class accuracies:
- no-match = 97.465%
- match = 92.982%
Average ROC AUC: 96.277%
Class ROC AUC:
- no-match = 97.308%
- match = 95.245%
NOTE: Replace fingerprint_signature_generator with the name of your model.
Running the model¶
Now that we have a trained model, it is time to run it in on an embedded device.
There are several different ways this can be done:
Using the command-line¶
The MLTK features the command:
mltk fingerprint_reader --help
Which will load the trained fingerprint model and execute it on the embedded device.
NOTE: Additional hardware is required to run this command, see Hardware Setup
To run program your model to an embedded device, issue the command:
mltk fingerprint_reader fingerprint_signature_generator --accelerator MVP
NOTE: Replace fingerprint_signature_generator with the name of your model.
Which will program the fingerprint_authenticator application and your model to the embedded device and run.
This command will also display images of the fingerprints captured from the fingerprint module.
Building the C++ example application¶
The MLTK supports building C++ Applications.
It also features an fingerprint_authenticator C++ application which can be built using:
Refer to the fingerprint_authenticator application’s documentation for how include your model into the built application.