Keyword Spotting - Pac-Man¶
This tutorial describes how to use the MLTK to develop a “Pac-Man” keyword spotting demo.
The basic setup for this demo is as follows:
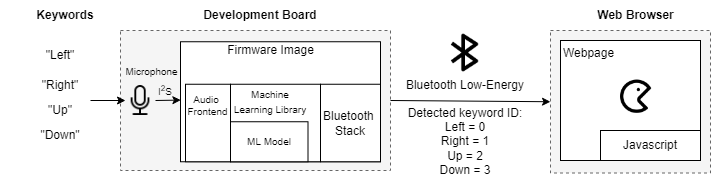
In the demo, embedded machine learning is used to detect the keywords:
Left
Right
Up
Down
Stop
Go
When a keyword is detected, its corresponding ID is sent to a webpage via Bluetooth Low-Energy. The webpage uses Javascript to process keyword ID to move the Pac-Man accordingly.
Live Demo¶
A live demo for this tutorial is available online:
https://mltk-pacman.web.app
NOTE: To use this demo, you must have a BRD2601 development board.
Quick Links¶
GitHub Source - View this tutorial on Github
Train in the “Cloud” - Vastly improve training times by training this model in the “cloud”
C++ Example Application - View this tutorial’s associated C++ example application
Pac-Man Webpage Source - View the Pac-Man webpage’s source code on Github
Machine Learning Model - View this tutorial’s associated machine learning model
Live Demo - Play Pac-Man using the keywords: Left, Right, Up, Down
Presentation PDF - Presentation describing how this demo was created
Presentation Video - YouTube video of the presentation given to TinyML.org for this tutorial
Overview¶
Objectives¶
After completing this tutorial, you will have:
A better understanding of how audio classification machine learning models work
All of the tools needed to develop your own keyword spotting model
A better understanding of how to issue commands to a webpage from an embedded MCU via Bluetooth Low Energy
A working demo to play the game Pac-Man using the keywords: “Left”, “Right”, “Up”, “Down”, “Stop”, “Go”
Content¶
This tutorial is divided into the following sections:
Running this tutorial from the command-line¶
While this tutorial uses a Notebook for documentation purposes, it must be ran from the command-line.
See the Standard Python Package Installation guide for more details on how to enable the mltk command in your local terminal.
Required Hardware¶
To play this tutorial’s game using machine learning + keyword spotting, the BRD2601 development board is required.
Install MLTK Python Package¶
Before using the MLTK, it must first be installed.
See the Installation Guide for more details.
!pip install --upgrade silabs-mltk
All MLTK modeling operations are accessible via the mltk command.
Run the command mltk --help to ensure it is working.
NOTE: The exclamation point ! tells the Notebook to run a shell command, it is not required in a standard terminal
!mltk --help
Usage: mltk [OPTIONS] COMMAND [ARGS]...
Silicon Labs Machine Learning Toolkit
This is a Python package with command-line utilities and scripts to aid the
development of machine learning models for Silicon Lab's embedded platforms.
Options:
--version Display the version of this mltk package and exit
--gpu / --no-gpu Disable usage of the GPU.
This does the same as defining the environment variable: CUDA_VISIBLE_DEVICES=-1
Example:
mltk --no-gpu train image_example1
--help Show this message and exit.
Commands:
build MLTK build commands
classify_audio Classify keywords/events detected in a microphone's...
classify_image Classify images detected by a camera connected to...
commander Silab's Commander Utility
compile Compile a model for the specified accelerator
custom Custom Model Operations
evaluate Evaluate a trained ML model
fingerprint_reader View/save fingerprints captured by the fingerprint...
profile Profile a model
quantize Quantize a model into a .tflite file
summarize Generate a summary of a model
train Train an ML model
update_params Update the parameters of a previously trained model
utest Run the all unit tests
view View an interactive graph of the given model in a...
view_audio View the spectrograms generated by the...
Prerequisite Reading¶
Before continuing with this tutorial, it is recommended to review the following documentation:
Keyword Spotting Overview - Provides overview of how embedded keyword spotting works
Keyword Spotting Tutorial - Provides an in-depth tutorial on how to create a keyword spotting model
Creating the Machine Learning Model¶
The pre-defined Model Specification used by the tutorial may be found on Github.
This model is a standard audio classification model designed to detect the classes:
Left
Right
Up
Down
Stop
Go
unknown
Additionally, this model augments the training samples by adding audio recorded while playing the Pac-Man game. In this way, the model can be more robust to the background noise generated while playing the game.
Refer to the model, keyword_spotting_pacman_v3 for more details.
Select the dataset¶
This model was trained using several different datasets:
mltk.datasets.audio.direction_commands - Synthetically generated keywords: left, right, up, down, stop, go
mltk.datasets.audio.speech_commands_v2 - Human generated keywords: left, right, up, down, stop, go
mltk.datasets.audio.mlcommons.ml_commons_keyword - Large collection of keywords, random subset used for unknown class
mltk.datasets.audio.background_noise.esc50 - Collection of various noises, random subset used for unknown class
mltk.datasets.audio.background_noise.ambient - Collection of various background noises, mixed into other samples for augmentation
mltk.datasets.audio.background_noise.brd2601 - “Silence” recorded by BRD2601 microphone, mixed into other samples to make them “sound” like they came from the BRD2601’s microphone
Pac-Man game noise - Recording from Pac-Man game play, mixed into other samples for augmentation
Model Parameter Tradeoffs¶
We have two main requirements when choosing the model parameters:
We want the spectrogram resolution and convolutional filters to be as high as possible so that the model can make accurate predictions
We want the model’s computational complexity to be as small as possible so that inference latency is small and keywords are quickly detected while playing the game
Note that the larger the spectrogram resolution, the larger the model’s input size and thus the larger the model’s computational complexity. Likewise, more convolution filters also increases the model’s computational complexity. As such, we need to find a middle ground for these parameters.
The MLTK offers two tools that can help when choosing these parameters:
Model Profiler - This allows for profiling the model on the embedded device and determining the inference latency before fully training the model
Audio Visualizer Utility - This allows for visualizing the generated spectrograms in real-time
Audio Feature Generator Settings¶
This model uses the following Audio Feature Generator settings:
from mltk.core.preprocess.audio.audio_feature_generator import AudioFeatureGeneratorSettings
frontend_settings = AudioFeatureGeneratorSettings()
frontend_settings.sample_rate_hz = 16000
frontend_settings.sample_length_ms = 1000 # A 1s buffer should be enough to capture the keywords
frontend_settings.window_size_ms = 30
frontend_settings.window_step_ms = 10
frontend_settings.filterbank_n_channels = 104 # We want this value to be as large as possible
# while still allowing for the ML model to execute efficiently on the hardware
frontend_settings.filterbank_upper_band_limit = 7500.0
frontend_settings.filterbank_lower_band_limit = 125.0 # The dev board mic seems to have a lot of noise at lower frequencies
frontend_settings.noise_reduction_enable = True # Enable the noise reduction block to help ignore background noise in the field
frontend_settings.noise_reduction_smoothing_bits = 10
frontend_settings.noise_reduction_even_smoothing = 0.025
frontend_settings.noise_reduction_odd_smoothing = 0.06
frontend_settings.noise_reduction_min_signal_remaining = 0.40 # This value is fairly large (which makes the background noise reduction small)
# But it has been found to still give good results
# i.e. There is still some background noise reduction,
# but the actual signal is still (mostly) untouched
frontend_settings.dc_notch_filter_enable = True # Enable the DC notch filter, to help remove the DC signal from the dev board's mic
frontend_settings.dc_notch_filter_coefficient = 0.95
frontend_settings.quantize_dynamic_scale_enable = True # Enable dynamic quantization, this dynamically converts the uint16 spectrogram to int8
frontend_settings.quantize_dynamic_scale_range_db = 40.0
This uses a 16kHz sample rate which was found to give better performance at the expense of more RAM.
frontend_settings.sample_rate_hz = 16000
To help reduce the model computational complexity, only a 1000ms sample length is used.
frontend_settings.sample_length_ms = 1000
The idea here is that it only takes at most ~1000ms to say any of the keywords (i.e. the audio buffer needs to be large enough to hold the entire keyword but no larger).
This model uses a window size of 30ms and a step of 10ms.
frontend_settings.window_size_ms = 30
frontend_settings.window_step_ms = 10
These values were found experimentally using the Audio Visualizer Utility.
104 frequency bins are used to generate the spectrogram:
frontend_settings.filterbank_n_channels = 104
Increasing this value improves the resolution of spectrogram at the cost of model computational complexity (i.e. inference latency).
The noise reduction block is enabled but uses a fairly large min_signal_remaining:
frontend_settings.noise_reduction_enable = True
frontend_settings.noise_reduction_smoothing_bits = 10
frontend_settings.noise_reduction_even_smoothing = 0.025
frontend_settings.noise_reduction_odd_smoothing = 0.06
frontend_settings.noise_reduction_min_signal_remaining = 0.40
This helps to reduce background noise in the field.
NOTE: We also add padding to the audio samples during training to “warm up” the noise reduction block when generating the spectrogram using the
Audio Feature Generator. See the audio_pipeline_with_augmentations()
function in keyword_spotting_pacman_v3.py for more details.
The DC notch filter was enabled to help remove the DC component from the development board’s microphone:
frontend_settings.dc_notch_filter_enable = True # Enable the DC notch filter
frontend_settings.dc_notch_filter_coefficient = 0.95
Dynamic quantization was enabled to convert the generated spectrogram from uint16 to int8
frontend_settings.quantize_dynamic_scale_enable = True # Enable dynamic quantization
frontend_settings.quantize_dynamic_scale_range_db = 40.0
Module Architecture¶
The model is based on the Temporal efficient neural network (TENet) model architecture.
A network for processing spectrogram data using temporal and depthwise convolutions. The network treats the [T, F] spectrogram as a timeseries shaped [T, 1, F].
More details at mltk.models.shared.tenet.TENet
def my_model_builder(model: MyModel) -> tf.keras.Model:
"""Build the Keras model
"""
input_shape = model.input_shape
# NOTE: This model requires the input shape: <time, 1, features>
# while the embedded device expects: <time, features, 1>
# Since the <time> axis is still row-major, we can swap the <features> with 1 without issue
time_size, feature_size, _ = input_shape
input_shape = (time_size, 1, feature_size)
keras_model = tenet.TENet12(
input_shape=input_shape,
classes=model.n_classes,
channels=40,
blocks=5,
)
keras_model.compile(
loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001, epsilon=1e-8),
metrics= ['accuracy']
)
return keras_model
The main parameters to modify are:
channels = 40
blocks = 5
channels sets the base number of channels in the network.
block set the number of (StridedIBB -> IBB -> ...) blocks in the networks.
The larger these values are, the more trainable parameters the model will have which should allow for it to have better accuracy. However, increasing this value also increases the model’s computational complexity which increases the model inference latency.
Audio Data Generator¶
This model has an additional requirement that the keywords need to be said while the Pac-Man video game noises are generated in the background. As such, the model is trained by taking each keyword sample and adding a snippet of background noise to the sample. In this way, the model learns to pick out the keywords from the Pac-Man video game’s noises.
The Pac-Man game audio was acquired by recording during game play (using the arrows on the keyboard). Recording was done using the MLTK command:
mltk classify_audio keyword_spotting_pacman_v3 --dump-audio --device
This command uses the microphone on the development board to record the video game’s generated audio. The recorded audio is saved to the local PC as a .wav file.
The model specification file was then modified to apply random augmentations to the dataset samples and then generate spectrograms from the augmented samples. The spectrograms are given to the model for training.
NOTE: The spectrogram generation algorithm source code is shared between the model training script and embedded runtime. This way, the generated spectrograms “look” the same during training and inference which should make the model more robust in the field.
The complete data pipeline is illustrated as follows:
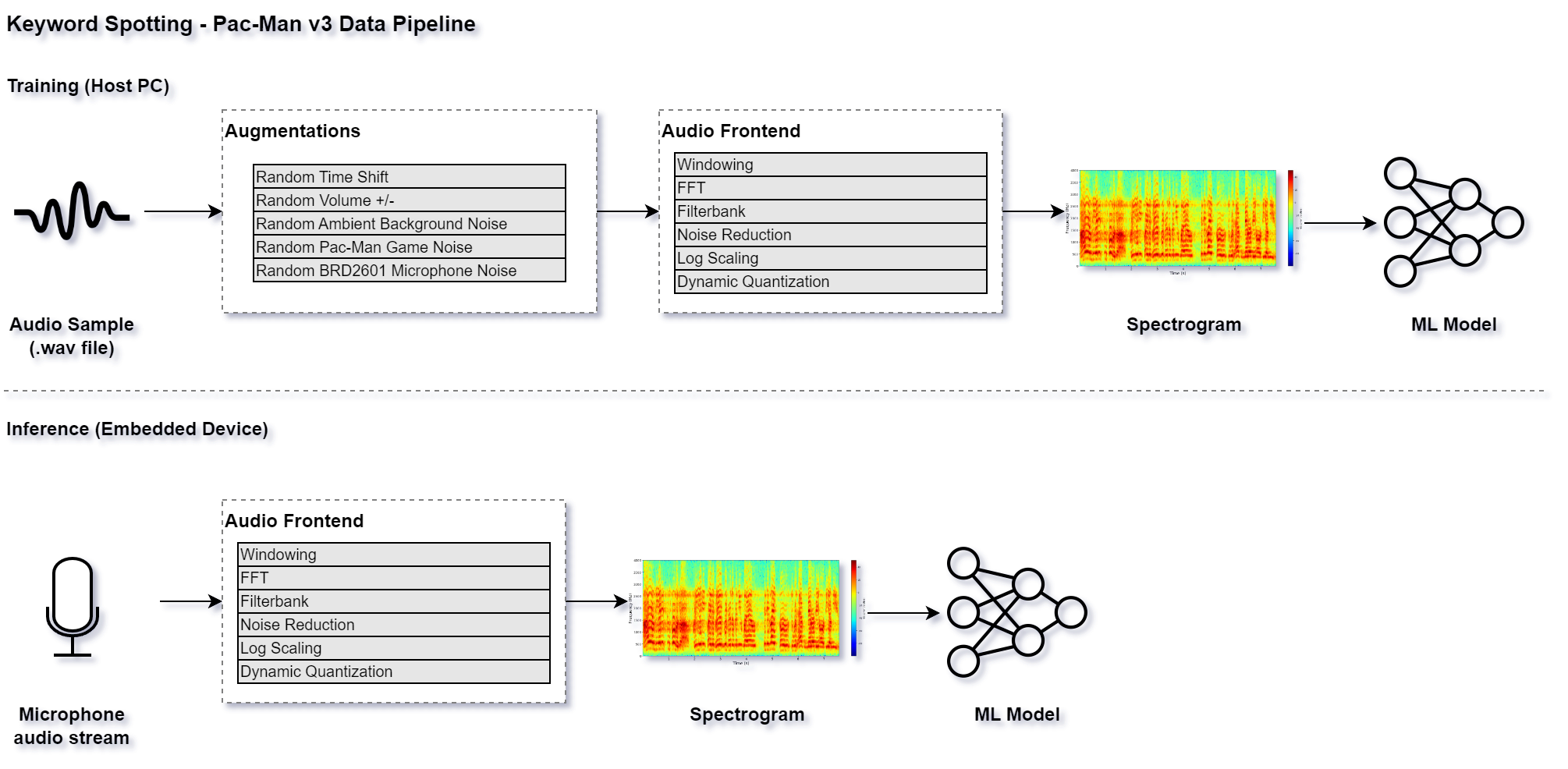
def audio_pipeline_with_augmentations(
path_batch:np.ndarray,
label_batch:np.ndarray,
seed:np.ndarray
) -> np.ndarray:
"""Augment a batch of audio clips and generate spectrograms
This does the following, for each audio file path in the input batch:
1. Read audio file
2. Adjust its length to fit within the specified length
3. Apply random augmentations to the audio sample using audiomentations
4. Convert to the specified sample rate (if necessary)
5. Generate a spectrogram from the augmented audio sample
6. Dump the augmented audio and spectrogram (if necessary)
NOTE: This will be execute in parallel across *separate* subprocesses.
Arguments:
path_batch: Batch of audio file paths
label_batch: Batch of corresponding labels
seed: Batch of seeds to use for random number generation,
This ensures that the "random" augmentations are reproducible
Return:
Generated batch of spectrograms from augmented audio samples
"""
batch_length = path_batch.shape[0]
height, width = frontend_settings.spectrogram_shape
x_shape = (batch_length, height, 1, width)
x_batch = np.empty(x_shape, dtype=np.int8)
# This is the amount of padding we add to the beginning of the sample
# This allows for "warming up" the noise reduction block
padding_length_ms = 1000
padded_frontend_settings = frontend_settings.copy()
padded_frontend_settings.sample_length_ms += padding_length_ms
# For each audio sample path in the current batch
for i, (audio_path, labels) in enumerate(zip(path_batch, label_batch)):
class_id = np.argmax(labels)
np.random.seed(seed[i])
rn = np.random.random()
# 3% of the time we want to replace the "unknown" sample with silence
if class_id == unknown_class_id and rn < 0.03:
original_sample_rate = frontend_settings.sample_rate_hz
sample = np.zeros((original_sample_rate,), dtype=np.float32)
audio_path = 'silence.wav'.encode('utf-8')
else:
# Read the audio file
try:
sample, original_sample_rate = audio_utils.read_audio_file(audio_path, return_numpy=True, return_sample_rate=True)
except Exception as e:
raise RuntimeError(f'Failed to read: {audio_path}, err: {e}')
# Create a buffer to hold the padded sample
padding_length = int((original_sample_rate * padding_length_ms) / 1000)
padded_sample_length = int((original_sample_rate * padded_frontend_settings.sample_length_ms) / 1000)
padded_sample = np.zeros((padded_sample_length,), dtype=np.float32)
# Adjust the audio clip to the length defined in the frontend_settings
out_length = int((original_sample_rate * frontend_settings.sample_length_ms) / 1000)
sample = audio_utils.adjust_length(
sample,
out_length=out_length,
trim_threshold_db=30,
offset=np.random.uniform(0, 1)
)
padded_sample[padding_length:padding_length+len(sample)] += sample
# Initialize the global audio augmentations instance
# NOTE: We want this to be global so that we only initialize it once per subprocess
audio_augmentations = globals().get('audio_augmentations', None)
if audio_augmentations is None:
audio_augmentations = audiomentations.Compose(
p=1.0,
transforms=[
audiomentations.Gain(min_gain_in_db=0.95, max_gain_in_db=1.2, p=1.0),
audiomentations.AddBackgroundNoise(
f'{dataset_dir}/_background_noise_/ambient',
min_snr_in_db=-1, # The lower the SNR, the louder the background noise
max_snr_in_db=35,
noise_rms="relative",
lru_cache_size=50,
p=0.80
),
audiomentations.AddBackgroundNoise(
f'{dataset_dir}/_background_noise_/pacman',
min_absolute_rms_in_db=-60,
max_absolute_rms_in_db=-35,
noise_rms="absolute",
lru_cache_size=50,
p=0.50
),
audiomentations.AddBackgroundNoise(
f'{dataset_dir}/_background_noise_/brd2601',
min_absolute_rms_in_db=-75.0,
max_absolute_rms_in_db=-60.0,
noise_rms="absolute",
lru_cache_size=50,
p=1.0
),
#audiomentations.AddGaussianSNR(min_snr_in_db=25, max_snr_in_db=40, p=0.25),
])
globals()['audio_augmentations'] = audio_augmentations
# Apply random augmentations to the audio sample
augmented_sample = audio_augmentations(padded_sample, original_sample_rate)
# Convert the sample rate (if necessary)
if original_sample_rate != frontend_settings.sample_rate_hz:
augmented_sample = audio_utils.resample(
augmented_sample,
orig_sr=original_sample_rate,
target_sr=frontend_settings.sample_rate_hz
)
# Ensure the sample values are within (-1,1)
augmented_sample = np.clip(augmented_sample, -1.0, 1.0)
# Generate a spectrogram from the augmented audio sample
spectrogram = audio_utils.apply_frontend(
sample=augmented_sample,
settings=padded_frontend_settings,
dtype=np.int8
)
# The input audio sample was padded with padding_length_ms of background noise
# Drop the padded background noise from the final spectrogram used for training
spectrogram = spectrogram[-height:, :]
# The output spectrogram is 2D, add a channel dimension to make it 3D:
# (height, width, channels=1)
# Convert the spectrogram dimension from
# <time, features> to
# <time, 1, features>
spectrogram = np.expand_dims(spectrogram, axis=-2)
x_batch[i] = spectrogram
return x_batch
Profiling the model¶
Before training a machine learning model, it is important to know how efficiently the model will execute on the embedded target. This is especially true when using keyword spotting to control a Pac-Man (a keyword that takes > 1s to detect will not be useful when trying to avoid the ghosts).
If the model inference takes too long to execute on the embedded target, then the model parameters need to be decreased to reduce the model’s computational complexity. The desired model parameters should be known before the model is fully trained.
To help determine the best model parameters, the MLTK features a Model Profiler command:
!mltk profile keyword_spotting_pacman_v3 --device --build --accelerator MVP
Profiling ML model on device ...
Profiling Summary
Name: my_model
Accelerator: MVP
Input Shape: 1x98x1x104
Input Data Type: int8
Output Shape: 1x7
Output Data Type: int8
Flash, Model File Size (bytes): 446.5k
RAM, Runtime Memory Size (bytes): 76.7k
Operation Count: 12.4M
Multiply-Accumulate Count: 6.0M
Layer Count: 90
Unsupported Layer Count: 0
Accelerator Cycle Count: 5.3M
CPU Cycle Count: 954.1k
CPU Utilization (%): 16.7
Clock Rate (hz): 78.0M
Time (s): 73.3m
Ops/s: 169.2M
MACs/s: 82.1M
Inference/s: 13.7
Model Layers
+-------+-------------------+--------+--------+------------+------------+----------+--------------------------+--------------+------------------------------------------------------+
| Index | OpCode | # Ops | # MACs | Acc Cycles | CPU Cycles | Time (s) | Input Shape | Output Shape | Options |
+-------+-------------------+--------+--------+------------+------------+----------+--------------------------+--------------+------------------------------------------------------+
| 0 | conv_2d | 2.5M | 1.2M | 928.9k | 11.3k | 11.8m | 1x98x1x104,40x3x1x104,40 | 1x98x1x40 | Padding:Same stride:1x1 activation:None |
| 1 | conv_2d | 976.1k | 470.4k | 390.2k | 5.2k | 5.0m | 1x98x1x40,120x1x1x40,120 | 1x98x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 2 | depthwise_conv_2d | 123.5k | 52.9k | 96.4k | 78.7k | 1.6m | 1x98x1x120,1x9x1x120,120 | 1x49x1x120 | Multiplier:1 padding:Same stride:2x2 activation:Relu |
| 3 | conv_2d | 472.4k | 235.2k | 185.3k | 5.3k | 2.4m | 1x49x1x120,40x1x1x120,40 | 1x49x1x40 | Padding:Valid stride:1x1 activation:None |
| 4 | conv_2d | 162.7k | 78.4k | 66.7k | 5.2k | 870.0u | 1x98x1x40,40x1x1x40,40 | 1x49x1x40 | Padding:Same stride:2x2 activation:Relu |
| 5 | add | 2.0k | 0 | 6.9k | 2.7k | 120.0u | 1x49x1x40,1x49x1x40 | 1x49x1x40 | Activation:Relu |
| 6 | conv_2d | 488.0k | 235.2k | 195.2k | 5.3k | 2.5m | 1x49x1x40,120x1x1x40,120 | 1x49x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 7 | depthwise_conv_2d | 123.5k | 52.9k | 94.5k | 78.5k | 1.6m | 1x49x1x120,1x9x1x120,120 | 1x49x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 8 | conv_2d | 472.4k | 235.2k | 185.3k | 5.3k | 2.4m | 1x49x1x120,40x1x1x120,40 | 1x49x1x40 | Padding:Valid stride:1x1 activation:None |
| 9 | add | 2.0k | 0 | 6.9k | 2.6k | 120.0u | 1x49x1x40,1x49x1x40 | 1x49x1x40 | Activation:Relu |
| 10 | conv_2d | 488.0k | 235.2k | 195.2k | 5.3k | 2.5m | 1x49x1x40,120x1x1x40,120 | 1x49x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 11 | depthwise_conv_2d | 123.5k | 52.9k | 94.5k | 78.5k | 1.6m | 1x49x1x120,1x9x1x120,120 | 1x49x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 12 | conv_2d | 472.4k | 235.2k | 185.3k | 5.3k | 2.4m | 1x49x1x120,40x1x1x120,40 | 1x49x1x40 | Padding:Valid stride:1x1 activation:None |
| 13 | add | 2.0k | 0 | 6.9k | 2.6k | 120.0u | 1x49x1x40,1x49x1x40 | 1x49x1x40 | Activation:Relu |
| 14 | conv_2d | 488.0k | 235.2k | 195.2k | 5.3k | 2.5m | 1x49x1x40,120x1x1x40,120 | 1x49x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 15 | depthwise_conv_2d | 123.5k | 52.9k | 94.5k | 78.5k | 1.6m | 1x49x1x120,1x9x1x120,120 | 1x49x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 16 | conv_2d | 472.4k | 235.2k | 185.3k | 5.3k | 2.4m | 1x49x1x120,40x1x1x120,40 | 1x49x1x40 | Padding:Valid stride:1x1 activation:None |
| 17 | add | 2.0k | 0 | 6.9k | 2.6k | 120.0u | 1x49x1x40,1x49x1x40 | 1x49x1x40 | Activation:Relu |
| 18 | conv_2d | 488.0k | 235.2k | 195.5k | 5.3k | 2.5m | 1x49x1x40,120x1x1x40,120 | 1x49x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 19 | depthwise_conv_2d | 63.0k | 27.0k | 47.9k | 40.6k | 810.0u | 1x49x1x120,1x9x1x120,120 | 1x25x1x120 | Multiplier:1 padding:Same stride:2x2 activation:Relu |
| 20 | conv_2d | 241.0k | 120.0k | 95.3k | 5.3k | 1.3m | 1x25x1x120,40x1x1x120,40 | 1x25x1x40 | Padding:Valid stride:1x1 activation:None |
| 21 | conv_2d | 83.0k | 40.0k | 34.4k | 5.2k | 480.0u | 1x49x1x40,40x1x1x40,40 | 1x25x1x40 | Padding:Same stride:2x2 activation:Relu |
| 22 | add | 1.0k | 0 | 3.5k | 2.6k | 90.0u | 1x25x1x40,1x25x1x40 | 1x25x1x40 | Activation:Relu |
| 23 | conv_2d | 249.0k | 120.0k | 99.9k | 5.3k | 1.3m | 1x25x1x40,120x1x1x40,120 | 1x25x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 24 | depthwise_conv_2d | 63.0k | 27.0k | 46.4k | 40.5k | 810.0u | 1x25x1x120,1x9x1x120,120 | 1x25x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 25 | conv_2d | 241.0k | 120.0k | 95.3k | 5.3k | 1.2m | 1x25x1x120,40x1x1x120,40 | 1x25x1x40 | Padding:Valid stride:1x1 activation:None |
| 26 | add | 1.0k | 0 | 3.5k | 2.6k | 90.0u | 1x25x1x40,1x25x1x40 | 1x25x1x40 | Activation:Relu |
| 27 | conv_2d | 249.0k | 120.0k | 99.7k | 5.3k | 1.3m | 1x25x1x40,120x1x1x40,120 | 1x25x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 28 | depthwise_conv_2d | 63.0k | 27.0k | 46.4k | 40.5k | 810.0u | 1x25x1x120,1x9x1x120,120 | 1x25x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 29 | conv_2d | 241.0k | 120.0k | 95.3k | 5.3k | 1.2m | 1x25x1x120,40x1x1x120,40 | 1x25x1x40 | Padding:Valid stride:1x1 activation:None |
| 30 | add | 1.0k | 0 | 3.5k | 2.6k | 60.0u | 1x25x1x40,1x25x1x40 | 1x25x1x40 | Activation:Relu |
| 31 | conv_2d | 249.0k | 120.0k | 99.9k | 5.3k | 1.3m | 1x25x1x40,120x1x1x40,120 | 1x25x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 32 | depthwise_conv_2d | 63.0k | 27.0k | 46.4k | 40.5k | 810.0u | 1x25x1x120,1x9x1x120,120 | 1x25x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 33 | conv_2d | 241.0k | 120.0k | 95.3k | 5.3k | 1.3m | 1x25x1x120,40x1x1x120,40 | 1x25x1x40 | Padding:Valid stride:1x1 activation:None |
| 34 | add | 1.0k | 0 | 3.5k | 2.6k | 60.0u | 1x25x1x40,1x25x1x40 | 1x25x1x40 | Activation:Relu |
| 35 | conv_2d | 249.0k | 120.0k | 99.9k | 5.3k | 1.3m | 1x25x1x40,120x1x1x40,120 | 1x25x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 36 | depthwise_conv_2d | 32.8k | 14.0k | 23.8k | 21.6k | 420.0u | 1x25x1x120,1x9x1x120,120 | 1x13x1x120 | Multiplier:1 padding:Same stride:2x2 activation:Relu |
| 37 | conv_2d | 125.3k | 62.4k | 49.6k | 5.3k | 660.0u | 1x13x1x120,40x1x1x120,40 | 1x13x1x40 | Padding:Valid stride:1x1 activation:None |
| 38 | conv_2d | 43.2k | 20.8k | 18.0k | 5.2k | 270.0u | 1x25x1x40,40x1x1x40,40 | 1x13x1x40 | Padding:Same stride:2x2 activation:Relu |
| 39 | add | 520.0 | 0 | 1.8k | 2.6k | 60.0u | 1x13x1x40,1x13x1x40 | 1x13x1x40 | Activation:Relu |
| 40 | conv_2d | 129.5k | 62.4k | 52.0k | 5.3k | 720.0u | 1x13x1x40,120x1x1x40,120 | 1x13x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 41 | depthwise_conv_2d | 32.8k | 14.0k | 22.4k | 21.6k | 420.0u | 1x13x1x120,1x9x1x120,120 | 1x13x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 42 | conv_2d | 125.3k | 62.4k | 49.6k | 5.3k | 660.0u | 1x13x1x120,40x1x1x120,40 | 1x13x1x40 | Padding:Valid stride:1x1 activation:None |
| 43 | add | 520.0 | 0 | 1.8k | 2.6k | 30.0u | 1x13x1x40,1x13x1x40 | 1x13x1x40 | Activation:Relu |
| 44 | conv_2d | 129.5k | 62.4k | 52.0k | 5.3k | 720.0u | 1x13x1x40,120x1x1x40,120 | 1x13x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 45 | depthwise_conv_2d | 32.8k | 14.0k | 22.4k | 21.6k | 420.0u | 1x13x1x120,1x9x1x120,120 | 1x13x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 46 | conv_2d | 125.3k | 62.4k | 49.6k | 5.3k | 690.0u | 1x13x1x120,40x1x1x120,40 | 1x13x1x40 | Padding:Valid stride:1x1 activation:None |
| 47 | add | 520.0 | 0 | 1.8k | 2.6k | 60.0u | 1x13x1x40,1x13x1x40 | 1x13x1x40 | Activation:Relu |
| 48 | conv_2d | 129.5k | 62.4k | 52.0k | 5.3k | 720.0u | 1x13x1x40,120x1x1x40,120 | 1x13x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 49 | depthwise_conv_2d | 32.8k | 14.0k | 22.4k | 21.6k | 420.0u | 1x13x1x120,1x9x1x120,120 | 1x13x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 50 | conv_2d | 125.3k | 62.4k | 49.6k | 5.3k | 660.0u | 1x13x1x120,40x1x1x120,40 | 1x13x1x40 | Padding:Valid stride:1x1 activation:None |
| 51 | add | 520.0 | 0 | 1.8k | 2.6k | 60.0u | 1x13x1x40,1x13x1x40 | 1x13x1x40 | Activation:Relu |
| 52 | conv_2d | 129.5k | 62.4k | 52.0k | 5.3k | 720.0u | 1x13x1x40,120x1x1x40,120 | 1x13x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 53 | depthwise_conv_2d | 17.6k | 7.6k | 11.8k | 12.1k | 240.0u | 1x13x1x120,1x9x1x120,120 | 1x7x1x120 | Multiplier:1 padding:Same stride:2x2 activation:Relu |
| 54 | conv_2d | 67.5k | 33.6k | 26.7k | 5.3k | 390.0u | 1x7x1x120,40x1x1x120,40 | 1x7x1x40 | Padding:Valid stride:1x1 activation:None |
| 55 | conv_2d | 23.2k | 11.2k | 9.7k | 5.2k | 180.0u | 1x13x1x40,40x1x1x40,40 | 1x7x1x40 | Padding:Same stride:2x2 activation:Relu |
| 56 | add | 280.0 | 0 | 992.0 | 2.6k | 30.0u | 1x7x1x40,1x7x1x40 | 1x7x1x40 | Activation:Relu |
| 57 | conv_2d | 69.7k | 33.6k | 28.1k | 5.3k | 420.0u | 1x7x1x40,120x1x1x40,120 | 1x7x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 58 | depthwise_conv_2d | 17.6k | 7.6k | 10.3k | 12.1k | 210.0u | 1x7x1x120,1x9x1x120,120 | 1x7x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 59 | conv_2d | 67.5k | 33.6k | 26.7k | 5.3k | 390.0u | 1x7x1x120,40x1x1x120,40 | 1x7x1x40 | Padding:Valid stride:1x1 activation:None |
| 60 | add | 280.0 | 0 | 992.0 | 2.6k | 30.0u | 1x7x1x40,1x7x1x40 | 1x7x1x40 | Activation:Relu |
| 61 | conv_2d | 69.7k | 33.6k | 28.1k | 5.3k | 420.0u | 1x7x1x40,120x1x1x40,120 | 1x7x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 62 | depthwise_conv_2d | 17.6k | 7.6k | 10.3k | 12.1k | 210.0u | 1x7x1x120,1x9x1x120,120 | 1x7x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 63 | conv_2d | 67.5k | 33.6k | 26.7k | 5.3k | 390.0u | 1x7x1x120,40x1x1x120,40 | 1x7x1x40 | Padding:Valid stride:1x1 activation:None |
| 64 | add | 280.0 | 0 | 992.0 | 2.6k | 30.0u | 1x7x1x40,1x7x1x40 | 1x7x1x40 | Activation:Relu |
| 65 | conv_2d | 69.7k | 33.6k | 28.1k | 5.3k | 420.0u | 1x7x1x40,120x1x1x40,120 | 1x7x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 66 | depthwise_conv_2d | 17.6k | 7.6k | 10.3k | 12.1k | 210.0u | 1x7x1x120,1x9x1x120,120 | 1x7x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 67 | conv_2d | 67.5k | 33.6k | 26.7k | 5.3k | 420.0u | 1x7x1x120,40x1x1x120,40 | 1x7x1x40 | Padding:Valid stride:1x1 activation:None |
| 68 | add | 280.0 | 0 | 992.0 | 2.6k | 30.0u | 1x7x1x40,1x7x1x40 | 1x7x1x40 | Activation:Relu |
| 69 | conv_2d | 69.7k | 33.6k | 28.1k | 5.3k | 420.0u | 1x7x1x40,120x1x1x40,120 | 1x7x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 70 | depthwise_conv_2d | 10.1k | 4.3k | 5.8k | 7.4k | 150.0u | 1x7x1x120,1x9x1x120,120 | 1x4x1x120 | Multiplier:1 padding:Same stride:2x2 activation:Relu |
| 71 | conv_2d | 38.6k | 19.2k | 15.3k | 5.3k | 240.0u | 1x4x1x120,40x1x1x120,40 | 1x4x1x40 | Padding:Valid stride:1x1 activation:None |
| 72 | conv_2d | 13.3k | 6.4k | 5.6k | 5.2k | 150.0u | 1x7x1x40,40x1x1x40,40 | 1x4x1x40 | Padding:Same stride:2x2 activation:Relu |
| 73 | add | 160.0 | 0 | 572.0 | 2.6k | 30.0u | 1x4x1x40,1x4x1x40 | 1x4x1x40 | Activation:Relu |
| 74 | conv_2d | 39.8k | 19.2k | 16.1k | 5.3k | 270.0u | 1x4x1x40,120x1x1x40,120 | 1x4x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 75 | depthwise_conv_2d | 10.1k | 4.3k | 4.3k | 7.3k | 120.0u | 1x4x1x120,1x9x1x120,120 | 1x4x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 76 | conv_2d | 38.6k | 19.2k | 15.3k | 5.3k | 270.0u | 1x4x1x120,40x1x1x120,40 | 1x4x1x40 | Padding:Valid stride:1x1 activation:None |
| 77 | add | 160.0 | 0 | 572.0 | 2.6k | 30.0u | 1x4x1x40,1x4x1x40 | 1x4x1x40 | Activation:Relu |
| 78 | conv_2d | 39.8k | 19.2k | 16.1k | 5.3k | 270.0u | 1x4x1x40,120x1x1x40,120 | 1x4x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 79 | depthwise_conv_2d | 10.1k | 4.3k | 4.3k | 7.3k | 120.0u | 1x4x1x120,1x9x1x120,120 | 1x4x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 80 | conv_2d | 38.6k | 19.2k | 15.3k | 5.3k | 240.0u | 1x4x1x120,40x1x1x120,40 | 1x4x1x40 | Padding:Valid stride:1x1 activation:None |
| 81 | add | 160.0 | 0 | 572.0 | 2.6k | 30.0u | 1x4x1x40,1x4x1x40 | 1x4x1x40 | Activation:Relu |
| 82 | conv_2d | 39.8k | 19.2k | 16.1k | 5.3k | 270.0u | 1x4x1x40,120x1x1x40,120 | 1x4x1x120 | Padding:Valid stride:1x1 activation:Relu |
| 83 | depthwise_conv_2d | 10.1k | 4.3k | 4.3k | 7.3k | 120.0u | 1x4x1x120,1x9x1x120,120 | 1x4x1x120 | Multiplier:1 padding:Same stride:1x1 activation:Relu |
| 84 | conv_2d | 38.6k | 19.2k | 15.3k | 5.3k | 240.0u | 1x4x1x120,40x1x1x120,40 | 1x4x1x40 | Padding:Valid stride:1x1 activation:None |
| 85 | add | 160.0 | 0 | 572.0 | 2.6k | 60.0u | 1x4x1x40,1x4x1x40 | 1x4x1x40 | Activation:Relu |
| 86 | average_pool_2d | 200.0 | 0 | 154.0 | 3.8k | 60.0u | 1x4x1x40 | 1x1x1x40 | Padding:Valid stride:1x4 filter:1x4 activation:None |
| 87 | reshape | 0 | 0 | 0 | 640.0 | 0 | 1x1x1x40,2 | 1x40 | Type=none |
| 88 | fully_connected | 567.0 | 280.0 | 477.0 | 2.1k | 30.0u | 1x40,7x40,7 | 1x7 | Activation:None |
| 89 | softmax | 35.0 | 0 | 0 | 5.5k | 90.0u | 1x7 | 1x7 | Type=softmaxoptions |
+-------+-------------------+--------+--------+------------+------------+----------+--------------------------+--------------+------------------------------------------------------+
Profiling time: 115.656699 seconds
This command builds the model then profiles it on the development board using the MVP hardware accelerator.
Training the model¶
Once the model specification is ready, it can be trained with the command:
!mltk train keyword_spotting_pacman_v3
Train in cloud¶
Alternatively, you can vastly improve the model training time by training this model in the “cloud”.
See the tutorial: Cloud Training with vast.ai for more details.
After training completes, a model archive file is generated containing the quantized .tflite model file. This is the file that is built into the firmware application.
Creating the Firmware Application¶
The BLE Audio Classifier C++ example application may be used with the train model.
The application uses the Audio Feature Generator library to generate spectrograms from the streaming microphone audio. The spectrograms are then passed to the Tensorflow-Lite Micro inference engine which uses the trained model from above to make predictions on if a keyword is found in the spectrogram. If a keyword is detected, a connected BLE client is sent a notification containing the detected class ID of the keyword and prediction probability.
Creating the Pac-Man Webpage¶
A Pac-Man Webpage is available that allows for playing the game “Pac-Man” using the keywords detected by the firmware application described above.
This webpage was adapted from a game created by Lucio Panpinto, view original source code on GitHub.
The webpage was modified to use the p5.ble.js library for communicating with the firmware application via Bluetooth Low Energy.
Running the Demo¶
With the following components complete:
Keyword spotting machine learning model
Firmware application with Audio Feature Generator, Tensorflow-Lite Micro, and Bluetooth libraries
Pac-Man webpage with Bluetooth
We can now run the demo.
A live demo may be found at: https://mltk-pacman.web.app.
Alternatively, you can build the firmware application from source and run the webpage locally:
Build firmware application from source¶
The MLTK supports building C++ Applications.
It also features a ble_audio_classifier C++ application which can be built using:
Refer to the ble_audio_classifier application’s documentation for how include your model into the built application.
Run webpage locally¶
The demo’s webpage uses “vanilla” javascript+css+html. No special build systems are required.
To run the webpage locally, simply open index.html in your web browser (NOTE: double-click the locally cloned index.html on your PC, not the one on Github).
When the webpage starts, follow the instructions but do not program the .s37. The locally built firmware application should have already been programmed as described in the the previous section.