Cloud Logging with Weights & Biases¶
This tutorial describes how to log the information generated during model development to the cloud. While many 3rd-party cloud solutions are available, this tutorial uses Weights & Biases:
Weights & Biases makes it easy to track your experiments, manage & version your data, and collaborate with your team so you can focus on building the best models.
This has the following benefits:
All model development files (trained model files, evaluation results, etc.) are saved to the cloud
Graphical interface for comparing different training runs
Sort training runs by custom configuration values to see which has the most benefit
View model training status from anywhere
Email alerts for when model training completes
Automatically generate model report (interactive webpage or PDF)
Monitor GPU and CPU usage during model training
Disclaimer¶
Weights & Biases is free for personal use but requires a paid subscription for commercial use.
See the Pricing Guide for more information.
Quick Links¶
Contents¶
This tutorial is divided into the following sections:
Basic Usage¶
The basic flow for logging information to the cloud is as follows:
Create a Weights & Biases account
Install the MLTK, see the Installation Guide:
pip install silabs-mltk
Install the Weights & Biases python package:
pip install wandb
Log into your wandb account using the command:
wandb loginDefine your MLTK model specification and extend the WeightsAndBiasesMixin, e.g.:
import mltk.core as mltk_core class MyModel( mltk_core.MltkModel, mltk_core.TrainMixin, mltk_core.DatasetMixin, mltk_core.EvaluateClassifierMixin, mltk_core.WeightsAndBiasesMixin ): pass my_model = MyModel()
Train your model with the command:
mltk train <model name> --post
Where
--posttells the MLTK to enable the WeightsAndBiasesMixinOptionally profile your model with the command:
mltk profile <model name> --accelerator mvp --device --post
Where
--posttells the MLTK to enable the WeightsAndBiasesMixin
That’s it! This will train (and optionally profile) the model and all relevant information will automatically be logged to the Weights & Biases cloud.
Logging Information¶
The WeightsAndBiasesMixin manages all of the details of initializing the wandb session and automatically logging the relavant information to the cloud.
Default Data¶
By default, the following information is logged to the cloud:
Model specification - The Python script that defines your model
Model archive - ZIP file containing the trained model files
Model summary - Basic informaation about the model
Dataset summary - Basic information about the dataset used for training and evaluation
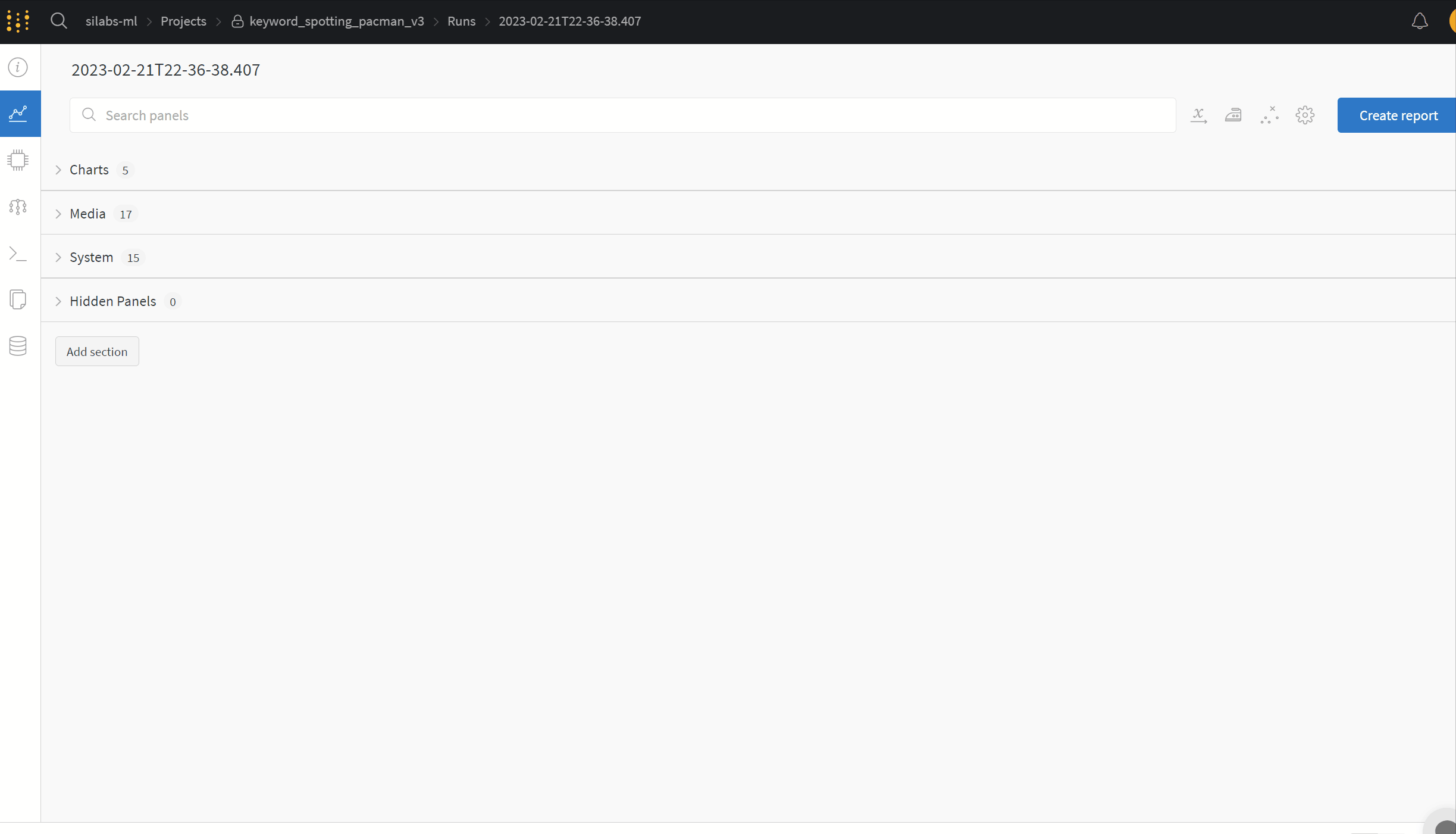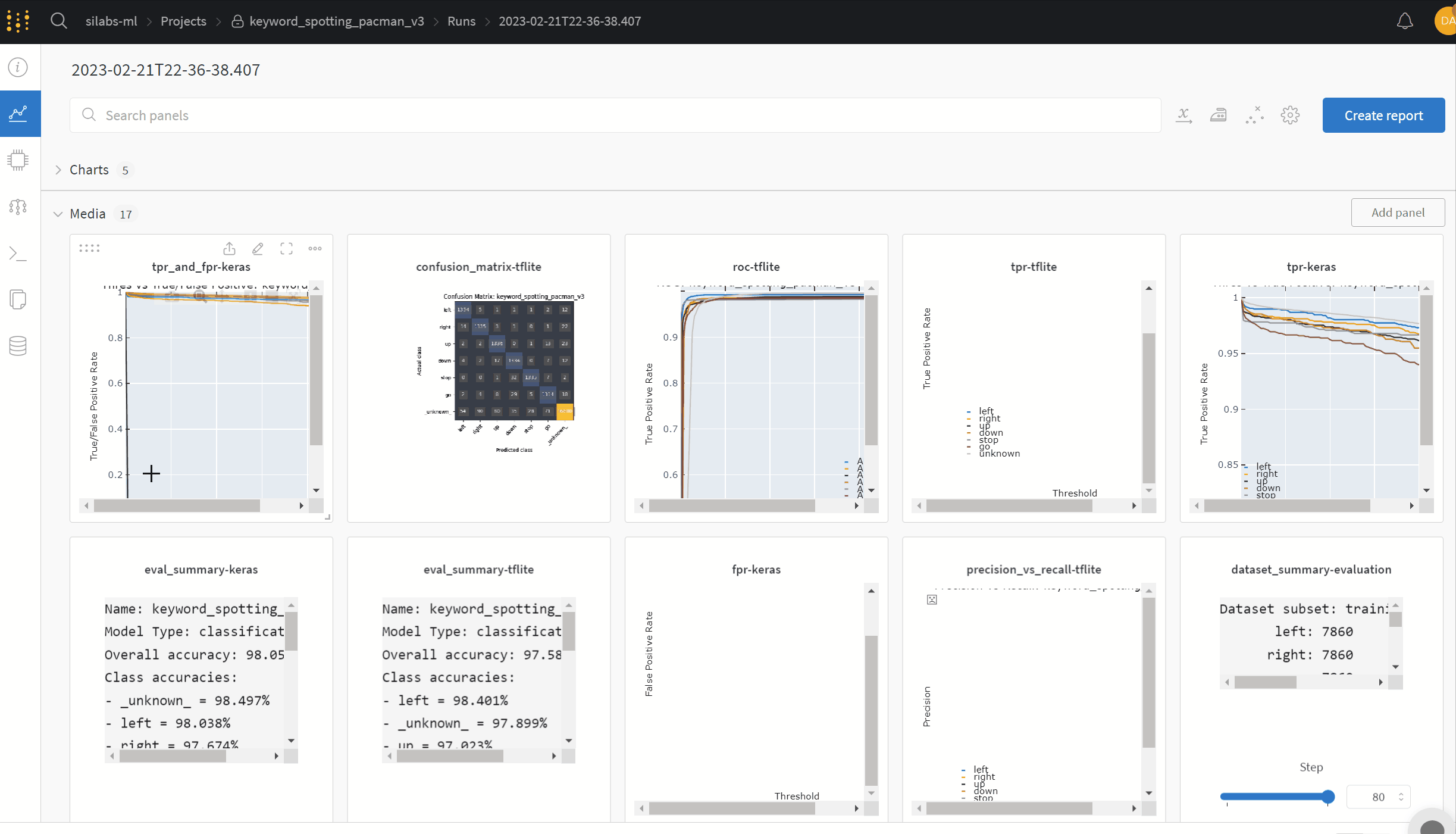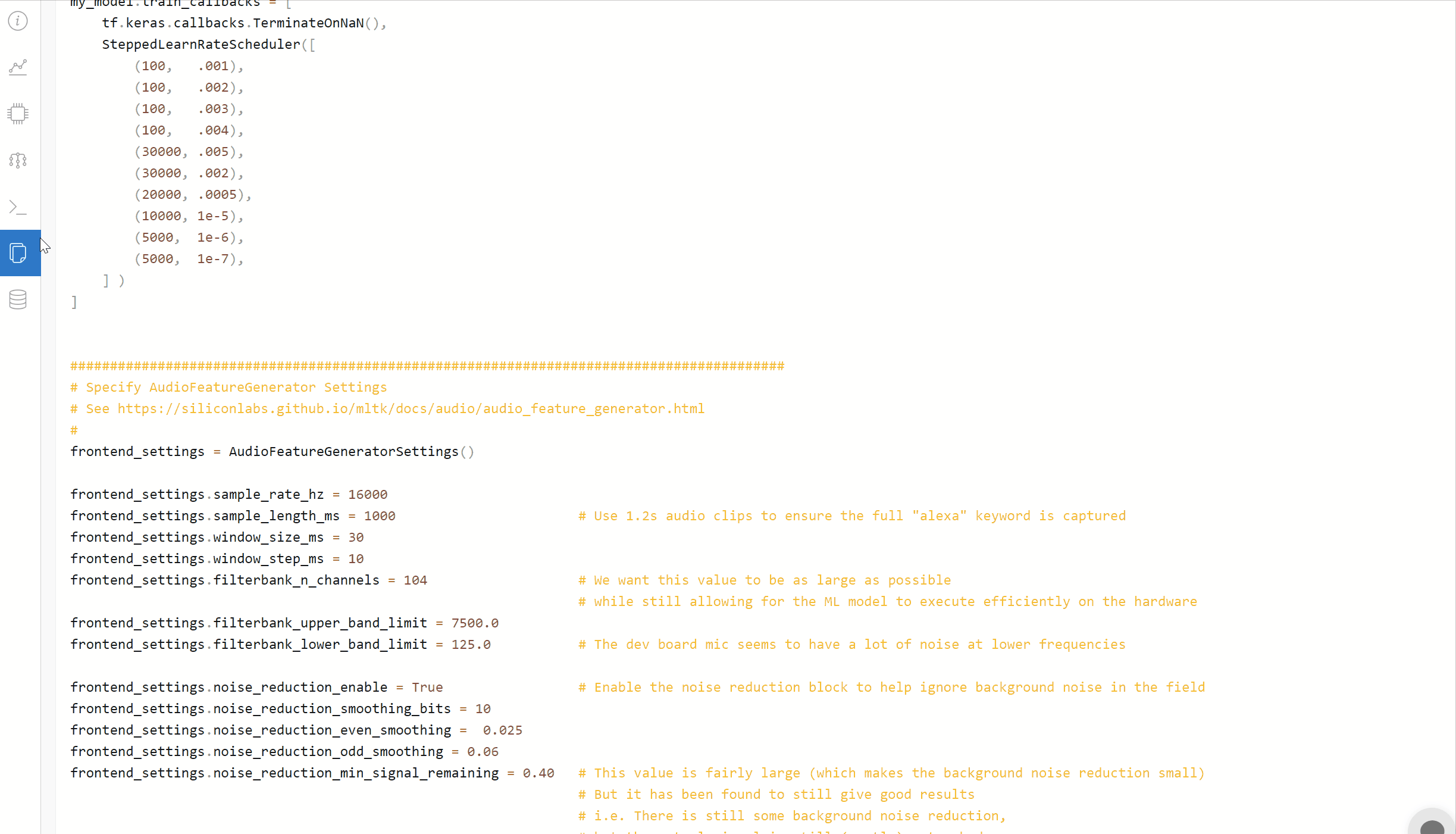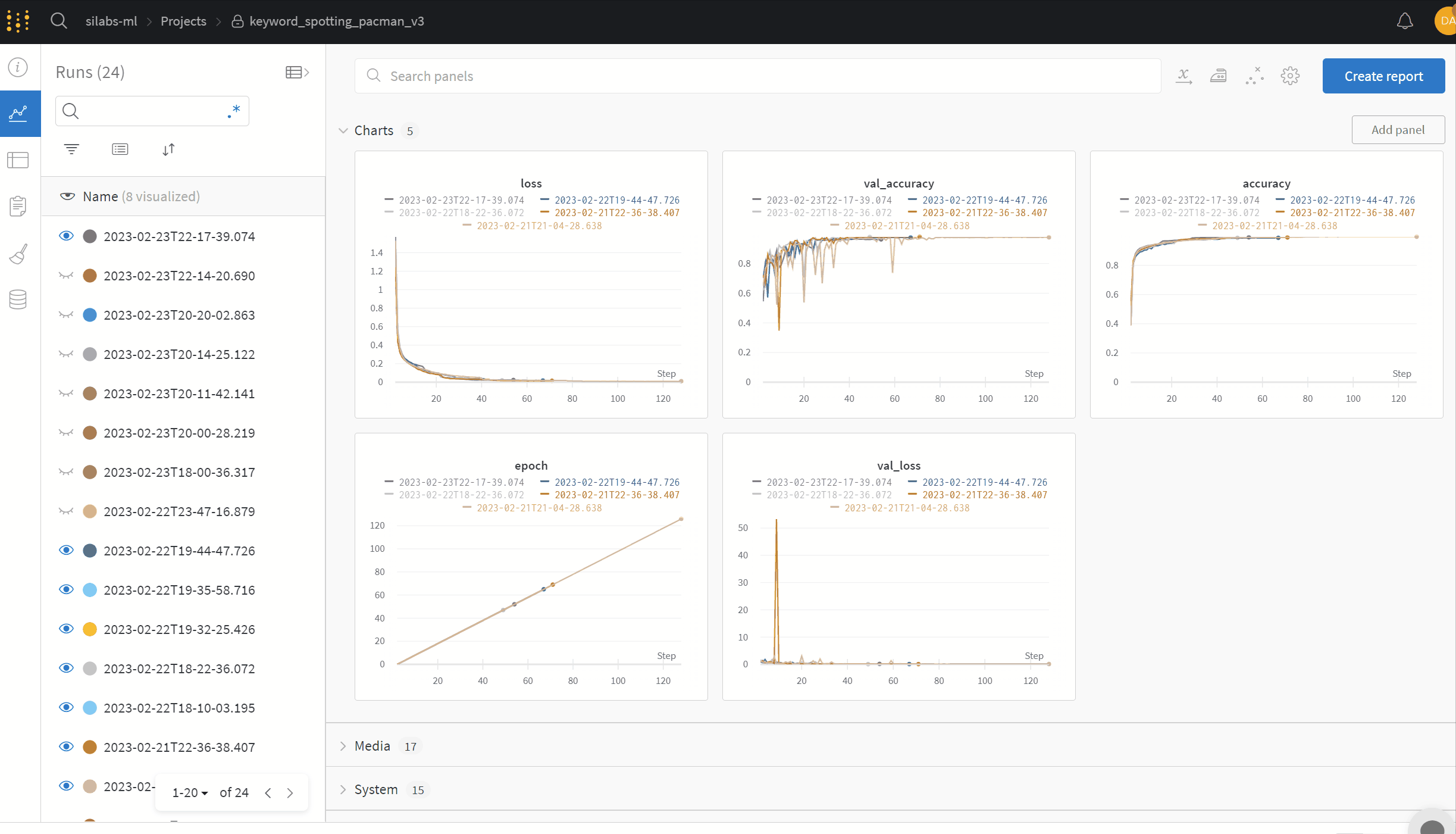
Training history - Learn rate, accuracy, loss, etc.
Evaluation results - Precision, recall, ROC, etc.
Profiling results - Inference/s, RAM and flash usage, etc.
System usage - GPU, CPU, disk, memory utilization, etc.
Custom Data¶
Any custom data can also be stored in the cloud using:
WeightsAndBiasesMixin.wandb_log() - post custom logging information
WeightsAndBiasesMixin.wandb_save() - upload a file
Internally, these APIs call the wandb APIs:
Training and logging in the cloud¶
The MLTK supports training via SSH.
This feature allows for model training in the cloud which can greatly reduce model training time.
See the Cloud Training via vast.ai tutorial for more details.
The following is needed to enable logging to Weight & Biases while training in the cloud:
Obtain your wandb API Key:
a. Log in to W&B
b. Collect your API key by navigating to the authorization pageCreate/modify the ~/.mltk/user_settings.yaml file and add:
ssh: startup_cmds: - pip install wandb plotly - wandb login <API KEY>
where
<API KEY>is your API key from step 1
That’s it! When you model trains on the cloud machine, it will also log to the Weights & Biases cloud.
This is especially useful when used in conjunction with the Alerts feature of W&B so you can be notified when training completes.
Other Features¶
The Weights & Biases documentation describes many useful features.
Some of the more useful features include:
Collaborative Reports - Reports let you organize, embed and automate visualizations, describe your findings, share updates with collaborators, and more.
Alerts - Send alerts, triggered from your Python code, to your Slack or email
Storing Artifacts - track datasets, models, dependencies, and results through each step of your machine learning pipeline. Artifacts make it easy to get a complete and auditable history of changes to your files.