fingerprint_signature_generator¶
Source code: fingerprint_signature_generator.py
Pre-trained model: fingerprint_signature_generator.mltk.zip.
This model was adapted from Image similarity estimation using a Siamese Network with a contrastive loss.
Siamese Networks are neural networks which share weights between two or more sister networks, each producing embedding vectors of its respective inputs.
In supervised similarity learning, the networks are then trained to maximize the contrast (distance) between embeddings of inputs of different classes, while minimizing the distance between embeddings of similar classes, resulting in embedding spaces that reflect the class segmentation of the training inputs.
Refer to the Fingerprint Authentication Tutorial for more details.
Commands¶
# Do a "dry run" test training of the model
mltk train fingerprint_signature_generator-test
# Train the model
mltk train fingerprint_signature_generator
# Evaluate the trained model .tflite model
mltk evaluate fingerprint_signature_generator --tflite
# Profile the model in the MVP hardware accelerator simulator
mltk profile fingerprint_signature_generator --accelerator MVP
# Profile the model on a physical development board
mltk profile fingerprint_signature_generator --accelerator MVP --device
# Model command to dump the preprocessed dataset
mltk custom fingerprint_signature_generator dump
# Model command to compare the raw vs preprocessed dataset images
mltk custom fingerprint_signature_generator preprocess --count 200
# Run this model in the fingerprint_reader application
mltk fingerprint_reader fingerprint_signature_generator --dump-images
Model Summary¶
mltk summarize fingerprint_signature_generator --tflite
+-------+-------------------+------------------+-----------------+-------------------------------------------------------+
| Index | OpCode | Input(s) | Output(s) | Config |
+-------+-------------------+------------------+-----------------+-------------------------------------------------------+
| 0 | depthwise_conv_2d | 180x180x1 (int8) | 88x88x8 (int8) | Multiplier:8 padding:valid stride:2x2 activation:relu |
| | | 5x5x8 (int8) | | |
| | | 8 (int32) | | |
| 1 | average_pool_2d | 88x88x8 (int8) | 44x44x8 (int8) | Padding:valid stride:2x2 filter:2x2 activation:none |
| 2 | conv_2d | 44x44x8 (int8) | 42x42x16 (int8) | Padding:valid stride:1x1 activation:relu |
| | | 3x3x8 (int8) | | |
| | | 16 (int32) | | |
| 3 | mean | 42x42x16 (int8) | 16 (int8) | Type=reduceroptions |
| | | 2 (int32) | | |
| 4 | fully_connected | 16 (int8) | 16 (int8) | Activation:none |
| | | 16 (int8) | | |
| | | 16 (int32) | | |
+-------+-------------------+------------------+-----------------+-------------------------------------------------------+
Total MACs: 3.581 M
Total OPs: 7.330 M
Name: fingerprint_signature_generator
Version: 1
Description: Fingerprint "signature" generator estimation using a Siamese Network with a contrastive loss
Classes: match, no-match
hash: c5b17e1deffd907e823bfadf519b2d5d
date: 2022-05-24T22:34:55.383Z
runtime_memory_size: 95964
threshold: 0.18000000715255737
sharpen_filter: b'þýýýþýýýýýýýdýýýýýýýþýýýþ'
sharpen_filter_width: 5
sharpen_filter_height: 5
sharpen_gain: 32
balance_threshold_max: 240
balance_threshold_min: 0
border: 32
verify_imin: 32
verify_imax: 224
verify_full_threshold: 3
verify_center_threshold: 2
samplewise_norm.rescale: 0.0
samplewise_norm.mean_and_std: False
.tflite file size: 6.5kB
Model Profiling Report¶
# Profile on physical EFR32xG24 using MVP accelerator
mltk profile fingerprint_signature_generator --device --accelerator MVP
Profiling Summary
Name: fingerprint_signature_generator
Accelerator: MVP
Input Shape: 1x180x180x1
Input Data Type: int8
Output Shape: 1x16
Output Data Type: int8
Flash, Model File Size (bytes): 6.4k
RAM, Runtime Memory Size (bytes): 143.0k
Operation Count: 7.5M
Multiply-Accumulate Count: 3.6M
Layer Count: 5
Unsupported Layer Count: 0
Accelerator Cycle Count: 4.1M
CPU Cycle Count: 5.4M
CPU Utilization (%): 57.4
Clock Rate (hz): 78.0M
Time (s): 119.7m
Ops/s: 62.7M
MACs/s: 29.8M
Inference/s: 8.4
Model Layers
+-------+-------------------+-------+--------+------------+------------+----------+-----------------------+--------------+-------------------------------------------------------+
| Index | OpCode | # Ops | # MACs | Acc Cycles | CPU Cycles | Time (s) | Input Shape | Output Shape | Options |
+-------+-------------------+-------+--------+------------+------------+----------+-----------------------+--------------+-------------------------------------------------------+
| 0 | depthwise_conv_2d | 3.3M | 1.5M | 2.5M | 33.2k | 31.5m | 1x180x180x1,1x5x5x8,8 | 1x88x88x8 | Multiplier:8 padding:valid stride:2x2 activation:relu |
| 1 | average_pool_2d | 77.4k | 0 | 54.3k | 1.8M | 23.8m | 1x88x88x8 | 1x44x44x8 | Padding:valid stride:2x2 filter:2x2 activation:none |
| 2 | conv_2d | 4.1M | 2.0M | 1.6M | 10.6k | 20.4m | 1x44x44x8,16x3x3x8,16 | 1x42x42x16 | Padding:valid stride:1x1 activation:relu |
| 3 | mean | 0 | 0 | 0 | 3.5M | 43.9m | 1x42x42x16,2 | 1x16 | Type=reduceroptions |
| 4 | fully_connected | 528.0 | 256.0 | 496.0 | 2.2k | 30.0u | 1x16,16x16,16 | 1x16 | Activation:none |
+-------+-------------------+-------+--------+------------+------------+----------+-----------------------+--------------+-------------------------------------------------------+
Model Diagram¶
mltk view fingerprint_signature_generator --tflite
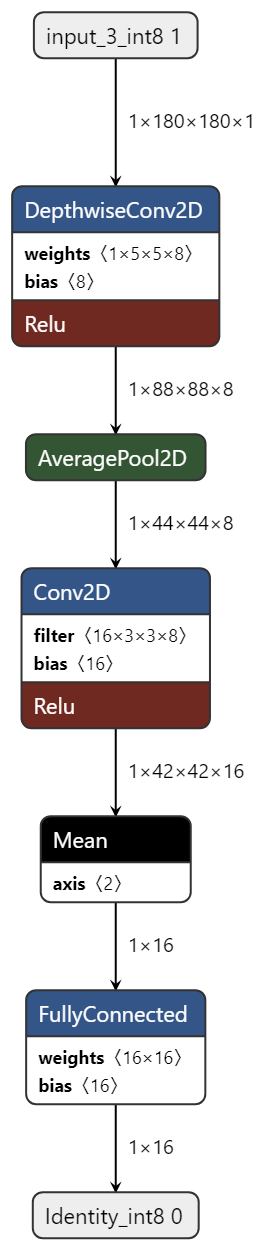
Model Specification¶
import os
from typing import Union, Tuple
import logging
import tqdm
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import typer
import matplotlib.pyplot as plt
from mltk.core.keras import (img_to_array, load_img)
from mltk.core.model import (
MltkModel,
TrainMixin,
ImageDatasetMixin,
EvaluateMixin
)
from mltk.core import (
load_tflite_or_keras_model,
KerasModel,
TfliteModel,
EvaluationResults,
ClassifierEvaluationResults,
TrainingResults
)
from mltk.core.tflite_model.tflite_model import TfliteModel
from mltk.core.preprocess.image.parallel_generator import ParallelImageDataGenerator, ParallelProcessParams
from mltk.core.keras.losses import ContrastiveLoss
from mltk.models.siliconlabs.fingerprint_signature_generator_dataset import (
FingerprintSignatureGeneratorDataset,
euclidean_distance
)
# @mltk_model # NOTE: This tag is required for this model be discoverable
class MyModel(
MltkModel,
TrainMixin,
ImageDatasetMixin,
EvaluateMixin
):
pass
my_model = MyModel()
###################################################################################################
# General Model Settings
###################################################################################################
my_model.version = 1
my_model.description = 'Fingerprint "signature" generator estimation using a Siamese Network with a contrastive loss'
my_model.epochs = 100
my_model.batch_size = 16
my_model.loss = ContrastiveLoss(margin=1.0)
# We need to save reference to the custom loss function
# so that we can load the .h5 file
# See https://www.tensorflow.org/guide/keras/save_and_serialize#registering_the_custom_object
my_model.keras_custom_objects['ContrastiveLoss'] = ContrastiveLoss
my_model.keras_custom_objects['euclidean_distance'] = euclidean_distance
my_model.metrics = ['accuracy']
my_model.optimizer = 'adam'
my_model.reduce_lr_on_plateau = dict(
monitor='loss',
factor = 0.95,
patience = 1,
min_delta=1e-7,
verbose=1
)
# https://keras.io/api/callbacks/early_stopping/
# If the validation accuracy doesn't improve after 'patience' epochs then stop training
# my_model.early_stopping = dict(
# monitor = 'val_accuracy',
# patience = 15,
# verbose=1,
# min_delta=1e-3,
# restore_best_weights=True
# )
###################################################################################################
# Model Architecture
###################################################################################################
def build_model_tower(my_model: MyModel):
"""Build the one of the "tower's" of the siamese network
This is the ML model that is deployed to the device.
It takes a fingerprint grayscale image as an input
and returns a (hopefully) unique signature of the image.
"""
input = layers.Input(my_model.input_shape)
x = layers.Conv2D(8, (5, 5), strides=(2,2))(input)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.AveragePooling2D(pool_size=(2, 2))(x)
x = layers.Conv2D(16, (3, 3), strides=(1,1))(x)
x = layers.BatchNormalization()(x)
x = layers.Activation('relu')(x)
x = layers.GlobalAveragePooling2D()(x)
x = layers.Dense(16)(x) # This determines how long the fingerprint signature vector is
return keras.Model(input, x)
def my_model_builder(my_model: MyModel) -> KerasModel:
"""Build the siamese network model """
input_1 = layers.Input(my_model.input_shape)
input_2 = layers.Input(my_model.input_shape)
# As mentioned above, Siamese Network share weights between
# tower networks (sister networks). To allow this, we will use
# same embedding network for both tower networks.
embedding_network = build_model_tower(my_model)
tower_1 = embedding_network(input_1)
tower_2 = embedding_network(input_2)
merge_layer = layers.Lambda(euclidean_distance)([tower_1, tower_2])
normal_layer = tf.keras.layers.BatchNormalization()(merge_layer)
output_layer = layers.Dense(1, activation="sigmoid")(normal_layer)
keras_model = keras.Model(inputs=[input_1, input_2], outputs=output_layer)
keras_model.compile(
loss=my_model.loss,
optimizer=my_model.optimizer,
metrics=my_model.metrics
)
return keras_model
my_model.build_model_function = my_model_builder
###################################################################################################
# Dataset generation
###################################################################################################
# For every fingerprint in the datset,
# generate this many non-matching pairs
nomatch_multiplier = 5
my_model.class_mode = 'binary' # we have a signal sigmoid output, so must use a binary "class mode"
my_model.classes = ['match', 'no-match']
my_model.input_shape = (180, 180, 1) # We manually crop the image in crop_and_convert_from_uint8_to_int8()
my_model.target_size = (192, 192, 1) # Ths is the size of the images in the dataset,
# We use the native image size to do all augmentations
# Then in the preprocessing_function() callback we crop the image border
my_model.class_weights = 'balanced'
input_shape = my_model.input_shape
target_size = my_model.target_size
h_offset = (target_size[0] - input_shape[0]) // 2
w_offset = (target_size[1] - input_shape[1]) // 2
def crop_and_convert_from_uint8_to_int8(params:ParallelProcessParams, x:np.ndarray) -> np.ndarray:
# x is a float32 dtype but has an uint8 range
x = np.clip(x, 0, 255) # The data should already been in the uint8 range, but clip it just to be sure
x = x - 128 # Convert from uint8 to int8
x = x.astype(np.int8)
# Crop (target_size - input_shape)/2 pixels from the image border
x = x[h_offset:target_size[0]-h_offset, w_offset:target_size[1]-w_offset]
return np.nan_to_num(x)
my_model.datagen = ParallelImageDataGenerator(
cores=0.65,
debug=False,
dtype=np.float32, # NOTE: The dtype is float32 but the range is int8,
max_batches_pending=48,
validation_split= 0.1,
validation_augmentation_enabled=True,
preprocessing_function=crop_and_convert_from_uint8_to_int8,
#save_to_dir=my_model.create_log_dir('datagen_dump', delete_existing=True),
rotation_range=0,
width_shift_range=15,
height_shift_range=15,
#brightness_range=(0.50, 1.70),
#contrast_range=(0.50, 1.70),
fill_mode='constant',
cval=0xff,
noise=['gauss', 'poisson', 's&p'],
#zoom_range=(0.95, 1.05),
# samplewise_center=True,
# samplewise_std_normalization=True,
rescale=None,
horizontal_flip=True,
vertical_flip=True
)
# NOTE: For privacy purposes, no dataset is provided for this model.
# As such, you must generate your own dataset to train this model.
# Refer to this model's corresponding tutorial for how to generate the dataset.
DATASET_ARCHIVE_URL = 'your-fingerprint-dataset-directory-or-download-url'
#DATASET_ARCHIVE_URL = '~/.mltk/fingerprint_reader/dataset'
DATASET_HASH = None
my_model.dataset = FingerprintSignatureGeneratorDataset(
dataset_path_or_url=DATASET_ARCHIVE_URL,
dataset_hash=DATASET_HASH,
nomatch_multiplier=nomatch_multiplier,
g_filter_size=5, # approximates radius of 2.5
g_filter_sigma=8,
contrast=2.0,
border=32,
balance_threshold_max=240,
balance_threshold_min=0,
verify_imin=32,
verify_imax=224,
verify_full_threshold=4,
verify_center_threshold=3
)
###################################################################################################
# Model Parameters
###################################################################################################
# The maximum "distance" between two signature vectors to be considered
# the same fingerprint
# Refer to the <model log dir>/eval/h5/threshold_vs_accuracy.png
# to get an idea of what this valid should be
my_model.model_parameters['threshold'] = 0.22
# Also add the preprocessing settings to the model parameters
preprocess_params = my_model.dataset.preprocess_params
my_model.model_parameters['sharpen_filter'] = my_model.dataset.sharpen_filter.flatten().tobytes()
my_model.model_parameters['sharpen_filter_width'] = my_model.dataset.sharpen_filter.shape[1]
my_model.model_parameters['sharpen_filter_height'] = my_model.dataset.sharpen_filter.shape[0]
my_model.model_parameters['sharpen_gain'] = my_model.dataset.sharpen_gain
my_model.model_parameters['balance_threshold_max'] = preprocess_params['balance_threshold_max']
my_model.model_parameters['balance_threshold_min'] = preprocess_params['balance_threshold_min']
my_model.model_parameters['border'] = preprocess_params['border']
my_model.model_parameters['verify_imin'] = preprocess_params['verify_imin']
my_model.model_parameters['verify_imax'] = preprocess_params['verify_imax']
my_model.model_parameters['verify_full_threshold'] = preprocess_params['verify_full_threshold']
my_model.model_parameters['verify_center_threshold'] = preprocess_params['verify_center_threshold']
###################################################################################################
# TF-Lite converter settings
###################################################################################################
def my_representative_dataset_generator():
"""This is called by the TfliteConverter
The data generator returns tuples of fingerprints
which is what is required to train the siamese network.
However, in my_keras_model_saver() we only save one of the "towers"
of the network (which is used to convert the fingerprint into a signature).
As such, to quantize the model we need to return a list of fingerprints (not tuples)
"""
for i, batch in enumerate(my_model.validation_data):
batch_x, batch_y, _ = keras.utils.unpack_x_y_sample_weight(batch)
batch_x0 = batch_x[0]
batch_x1 = batch_x[1]
# The TF-Lite converter expects 1 sample batches
for x0 in batch_x0:
yield [np.expand_dims(x0, axis=0)]
for x1 in batch_x1:
yield [np.expand_dims(x1, axis=0)]
if i > 50:
break
my_model.tflite_converter = dict(
optimizations=[tf.lite.Optimize.DEFAULT],
supported_ops=[tf.lite.OpsSet.TFLITE_BUILTINS_INT8],
inference_input_type=tf.int8,
inference_output_type=tf.int8,
representative_dataset=my_representative_dataset_generator,
experimental_new_converter =False,
experimental_new_quantizer =False
)
###################################################################################################
# Model Saver
###################################################################################################
def my_keras_model_saver(
mltk_model:MyModel,
keras_model:KerasModel,
logger:logging.Logger
) -> KerasModel:
"""This is invoked after training successfully completes
Here want to just save one of the "towers"
as that is what is used to generate the fingerprint signature
on the device
"""
# The given keras_model contains the full siamese network
# Save it to the model's log dir
h5_path = mltk_model.h5_log_dir_path
siamese_network_h5_path = h5_path[:-len('.h5')] + '.siamese.h5'
logger.debug(f'Saving {siamese_network_h5_path}')
keras_model.save(siamese_network_h5_path, save_format='tf')
# Extract the embedding network from the siamese network
embedding_network = None
for layer in keras_model.layers:
if layer.name == 'model':
embedding_network = layer
break
if embedding_network is None:
raise RuntimeError('Failed to find embedding model in siamese network model, does the embedding model have the name "model" ?')
# Return the keras model
return embedding_network
my_model.on_save_keras_model = my_keras_model_saver
###################################################################################################
# Model Evaluation
###################################################################################################
def generate_predictions(
mltk_model:MyModel,
built_model:Union[KerasModel, TfliteModel],
threshold:float,
x=None
) -> Tuple[np.ndarray,np.ndarray]:
"""Generate predictions using the dataset and trained model
A "prediction" is the euclidean distance between two fingerprint images.
If the distance is less than threshold then the fingerprints are considered
a match, otherwise they're not matching (i.e. they're not the same finger)
"""
def _compare_signatures(s1, s2) -> float:
# Calculate the distance (i.e. similarity)
# between the two fingerprint signature vectors
dis = np.sqrt(np.sum(np.square(s1 - s2)))
# If the distance is less than the threshold
# then the two signatures are considered a match
# Normalize the distance to be between 0,1
# where <0.5 maps to < threshold
return min((0.5/threshold) * dis, 1.0), dis
y_dis = []
y_pred = []
y_label = []
desc = ' Generating .h5 predictions' if isinstance(built_model, KerasModel) else 'Generating .tflite predictions'
# If this a .tflite model
# then we need to dequantize the model output.
# The input to the .tflite should have a scaler of 1 and zeropoint of 0
# (i.e. the model input expects the full int8 range)
# However, the model output does NOT use the full int8.
# Thus we need to use the output tensor's scaler and zeropoint to convert to the int8 range.
# HINT: look at the the .tflite in https://netron.app
# and view the quantization params for the input and output tensors.
# The TfliiteModel.predict() API will automatically do the de-quantization if
# we force the output dtype to be float32
kwargs = dict()
if isinstance(built_model, TfliteModel):
kwargs['y_dtype'] = np.float32
if x is not None:
with tqdm.tqdm(total=len(x), unit='prediction', desc=desc) as progbar:
for x0, x1 in x:
# For each fingerprint sample pair
# generate a "signature"
s0 = built_model.predict(np.expand_dims(x0, axis=0), **kwargs)[0]
s1 = built_model.predict(np.expand_dims(x1, axis=0), **kwargs)[0]
pred, dis = _compare_signatures(s0, s1)
y_pred.append(pred)
y_dis.append(dis)
progbar.update()
else:
with tqdm.tqdm(total=mltk_model.x.n, unit='prediction', desc=desc) as progbar:
for batch_x, batch_y in mltk_model.x:
batch_x0 = batch_x[0]
batch_x1 = batch_x[1]
batch_s0 = built_model.predict(batch_x0, **kwargs)
batch_s1 = built_model.predict(batch_x1, **kwargs)
for s0, s1, y in zip(batch_s0, batch_s1, batch_y):
pred, dis = _compare_signatures(s0, s1)
y_pred.append(pred)
y_dis.append(dis)
y_label.append(y)
progbar.update(mltk_model.x.batch_size)
y_pred = np.asarray(y_pred)
y_label = np.asarray(y_label)
return y_pred, y_label, y_dis
def collect_samples(my_model:MyModel, count:int) -> Tuple[list, list]:
"""Collect the specified number of samples from the dataset"""
my_model.datagen.debug = True
my_model.datagen.cores = 1
my_model.datagen.validation_split = None
my_model.load_dataset(subset='training')
if count == -1:
count = 1e12
match_samples = []
nomatch_samples = []
for batch_x, batch_y in my_model.x:
if len(match_samples) + len(nomatch_samples) >= count:
break
for x0, x1, y in zip(batch_x[0], batch_x[1], batch_y):
if y == 0 and len(match_samples) < count/2:
match_samples.append((x0, x1))
elif y == 1 and len(nomatch_samples) < count/2:
nomatch_samples.append((x0, x1))
my_model.unload_dataset()
all_x = match_samples + nomatch_samples
all_y = [0] * len(match_samples) + [1] * len(nomatch_samples)
return all_x, all_y
def my_model_evaluator(
mltk_model:MyModel,
built_model:Union[KerasModel, TfliteModel],
eval_dir:str,
logger:logging.Logger,
show:bool
) -> EvaluationResults:
"""Custom callback to evaluate the trained model
The model is effectively a classifier, but we need to do
a special step to compare the signatures in the dataset.
"""
results = ClassifierEvaluationResults(
name=mltk_model.name,
classes=mltk_model.classes
)
threshold = my_model.model_parameters['threshold']
logger.error(f'Using model threshold: {threshold}')
y_pred, y_label, y_dis = generate_predictions(
mltk_model,
built_model,
threshold
)
results.calculate(
y=y_label,
y_pred=y_pred,
)
results.generate_plots(
logger=logger,
output_dir=eval_dir,
show=show
)
match_dis = []
nomatch_dis = []
for y, dis in zip(y_label, y_dis):
if y == 0:
match_dis.append(dis)
else:
nomatch_dis.append(dis)
match_dis = sorted(match_dis)
match_dis_x = [i for i in range(len(match_dis))]
nomatch_dis = sorted(nomatch_dis)
nomatch_dis_x = [i for i in range(len(nomatch_dis))]
step = (match_dis[-1] - match_dis[0]) / 100
thresholds = np.arange(match_dis[0], match_dis[-1], step)
match_acc = []
nomatch_acc = []
for thres in thresholds:
valid_count = sum(x < thres for x in match_dis)
match_acc.append(valid_count / len(match_dis))
valid_count = sum(x > thres for x in nomatch_dis)
nomatch_acc.append(valid_count / len(nomatch_dis))
fig = plt.figure('Threshold vs Accuracy')
plt.plot(match_acc, thresholds, label='Match')
plt.plot(nomatch_acc, thresholds, label='Non-match')
#plt.ylim([0.0, 0.01])
plt.legend(loc="lower right")
plt.xlabel('Accuracy')
plt.ylabel('Threshold')
plt.title('Threshold vs Accuracy')
plt.grid(which='major')
if eval_dir:
output_path = f'{eval_dir}/threshold_vs_accuracy.png'
plt.savefig(output_path)
logger.info(f'Generated {output_path}')
if show:
plt.show(block=False)
else:
fig.clear()
plt.close(fig)
fig = plt.figure('Euclidean Distance')
plt.plot(match_dis_x, match_dis, label='Match')
plt.plot(nomatch_dis_x, nomatch_dis, label='Non-match')
plt.legend(loc="lower right")
plt.xlabel('Index')
plt.ylabel('Distance')
plt.title('Euclidean Distance')
plt.grid(which='major')
if eval_dir:
output_path = f'{eval_dir}/eclidean_distance.png'
plt.savefig(output_path)
logger.info(f'Generated {output_path}')
if show:
plt.show(block=False)
else:
fig.clear()
plt.close(fig)
return results
my_model.eval_custom_function = my_model_evaluator
###################################################################################################
# Custom model commands
###################################################################################################
@my_model.cli.command('dump')
def datagen_dump_custom_command(
tflite:bool = typer.Option(False, '--tflite',
help='Include the trained .tflite model predictions in the displayed results'
),
h5:bool = typer.Option(False, '--h5',
help='Include the trained .h5 model predictions in the displayed results'
),
count:int = typer.Option(20, '--count',
help='Number of samples to dump, -1 to dump all'
),
threshold:float = typer.Option(None, '--threshold',
help='Comparsion threshold. If omitted then use the threshold from the model'
),
):
"""Custom command to dump the dataset
\b
Invoke this command with:
mltk custom fingerprint_signature_generator dump
mltk custom fingerprint_signature_generator dump --tflite --h5 --count 200
"""
threshold = threshold or my_model.model_parameters['threshold']
dump_dir = my_model.create_log_dir('datagen_dump', delete_existing=True)
x_samples, y_samples = collect_samples(my_model, count=count)
tflite_y_pred = None
if tflite:
tflite_model = load_tflite_or_keras_model(my_model, model_type='tflite')
tflite_y_pred, _, _ = generate_predictions(
my_model,
tflite_model,
threshold=threshold,
x=x_samples
)
h5_y_pred = None
if h5:
keras_model = load_tflite_or_keras_model(my_model, model_type='h5')
h5_y_pred, _, _ = generate_predictions(
my_model,
keras_model,
threshold=threshold,
x=x_samples
)
with tqdm.tqdm(total=len(x_samples), unit='sample', desc=' Dumping samples') as progbar:
for i, x in enumerate(x_samples):
fig = plt.figure(figsize=(4, 2))
plt.axis('off')
label = 'match' if y_samples[i] == 0 else 'nomatch'
title = 'Match:' if y_samples[i] == 0 else 'Non-match:'
if tflite_y_pred is not None:
title += f' tflite={tflite_y_pred[i]:.3f},'
if h5_y_pred is not None:
title += f' keras={h5_y_pred[i]:.3f},'
plt.title(title[:-1])
ax = fig.add_subplot(1, 2, 1)
ax.imshow(x[0], cmap="gray")
ax.axis('off')
ax = fig.add_subplot(1, 2, 2)
ax.imshow(x[1], cmap="gray")
ax.axis('off')
fig.tight_layout()
plt.savefig(f'{dump_dir}/{label}-{i}.png')
plt.close(fig)
progbar.update()
print(f'Images dumped to {dump_dir}')
@my_model.cli.command('preprocess')
def preprocess_custom_command(
count:int = typer.Option(100, '--count',
help='Number of samples to dump, -1 to use all images'
),
):
"""Compare raw samples vs preprocessed samples
\b
Invoke this command with:
mltk custom fingerprint_signature_generator preprocess
mltk custom fingerprint_signature_generator preprocess --count 200
"""
dump_dir = my_model.create_log_dir('compare_preprocess', delete_existing=True)
dataset = my_model.dataset
dataset.preprocess_samples_enabled = False
unprocessed_dir = dataset.load_data()
all_samples = dataset.list_all_samples(unprocessed_dir, flatten=True)
if count == -1:
count = len(all_samples)
all_samples = all_samples[:min(count, len(all_samples))]
with tqdm.tqdm(total=len(all_samples), unit='sample', desc='Comparing samples') as progbar:
for fn in all_samples:
img = load_img(f'{unprocessed_dir}/{fn}', color_mode='grayscale')
unprocessed_img = img_to_array(img, dtype='uint8')
unprocessed_img = np.squeeze(unprocessed_img, axis=-1)
img.close()
processed_img = dataset.preprocess_sample(unprocessed_img)
img_valid = dataset.verify_sample(processed_img)
fig = plt.figure(figsize=(4, 4))
plt.axis('off')
name = os.path.basename(fn)
plt.title(name)
ax = fig.add_subplot(1, 2, 1)
ax.imshow(unprocessed_img, cmap="gray")
ax.axis('off')
ax = fig.add_subplot(1, 2, 2)
ax.imshow(processed_img, cmap="gray")
ax.axis('off')
#fig.tight_layout()
fig.text(.1, 0, dataset.previous_verify_msg)
plt.savefig(f'{dump_dir}/{"" if img_valid else "droppped-"}{name}')
plt.close(fig)
progbar.update()
print(f'Images dumped to {dump_dir}')
##########################################################################################
# The following allows for running this model training script directly, e.g.:
# python fingerprint_signature_generator.py
#
# Note that this has the same functionality as:
# mltk train fingerprint_signature_generator
#
if __name__ == '__main__':
import mltk.core as mltk_core
from mltk import cli
# Setup the CLI logger
cli.get_logger(verbose=False)
# If this is true then this will do a "dry run" of the model testing
# If this is false, then the model will be fully trained
test_mode_enabled = True
# Train the model
# This does the same as issuing the command: mltk train fingerprint_signature_generator-test --clean
train_results = mltk_core.train_model(my_model, clean=True, test=test_mode_enabled)
print(train_results)
# Evaluate the model against the quantized .h5 (i.e. float32) model
# This does the same as issuing the command: mltk evaluate fingerprint_signature_generator-test
tflite_eval_results = mltk_core.evaluate_model(my_model, verbose=True, test=test_mode_enabled)
print(tflite_eval_results)
# Profile the model in the simulator
# This does the same as issuing the command: mltk profile fingerprint_signature_generator-test
profiling_results = mltk_core.profile_model(my_model, test=test_mode_enabled)
print(profiling_results)