tflite_micro_speech¶
TF-Lite Micro Speech reference model
Source code: tflite_micro_speech.py
Pre-trained model: tflite_micro_speech.mltk.zip
Taken from: https://github.com/SiliconLabs/platform_ml_models/tree/master/eembc/TFLite_micro_speech
Dataset¶
Model Topology & Training¶
Performance (floating point model)¶
Accuracy - 93.7%
AUC - .993
Note
Performance is somewhat sensitive to the exact process of spectrogram generation. We may need to precisely define that.
Performance (quantized tflite model)¶
Accuracy - 93.1%
AUC -* .992
Commands¶
# Do a "dry run" test training of the model
mltk train tflite_micro_speech-test
# Train the model
mltk train tflite_micro_speech
# Evaluate the trained model .tflite model
mltk evaluate tflite_micro_speech --tflite
# Profile the model in the MVP hardware accelerator simulator
mltk profile tflite_micro_speech --accelerator MVP
# Profile the model on a physical development board
mltk profile tflite_micro_speech --accelerator MVP --device
Model Summary¶
mltk summarize tflite_micro_speech --tflite
+-------+-----------------+----------------+----------------+-----------------------------------------+
| Index | OpCode | Input(s) | Output(s) | Config |
+-------+-----------------+----------------+----------------+-----------------------------------------+
| 0 | conv_2d | 49x40x1 (int8) | 25x20x8 (int8) | Padding:same stride:2x2 activation:relu |
| | | 10x8x1 (int8) | | |
| | | 8 (int32) | | |
| 1 | reshape | 25x20x8 (int8) | 4000 (int8) | BuiltinOptionsType=0 |
| | | 2 (int32) | | |
| 2 | fully_connected | 4000 (int8) | 4 (int8) | Activation:none |
| | | 4000 (int8) | | |
| | | 4 (int32) | | |
| 3 | softmax | 4 (int8) | 4 (int8) | BuiltinOptionsType=9 |
+-------+-----------------+----------------+----------------+-----------------------------------------+
Total MACs: 336.000 k
Total OPs: 680.012 k
Name: tflite_micro_speech
Version: 1
Description: TFLite-Micro speech
Classes: yes, no, _unknown_, _silence_
hash: 36dd6db8f633c9fca61b418402ea698f
date: 2022-02-04T19:13:52.143Z
runtime_memory_size: 9028
average_window_duration_ms: 1000
detection_threshold: 185
suppression_ms: 1500
minimum_count: 3
volume_db: 5.0
latency_ms: 0
log_level: info
samplewise_norm.rescale: 0.0
samplewise_norm.mean_and_std: False
fe.sample_rate_hz: 16000
fe.sample_length_ms: 1000
fe.window_size_ms: 30
fe.window_step_ms: 20
fe.filterbank_n_channels: 40
fe.filterbank_upper_band_limit: 7500.0
fe.filterbank_lower_band_limit: 125.0
fe.noise_reduction_enable: True
fe.noise_reduction_smoothing_bits: 10
fe.noise_reduction_even_smoothing: 0.02500000037252903
fe.noise_reduction_odd_smoothing: 0.05999999865889549
fe.noise_reduction_min_signal_remaining: 0.05000000074505806
fe.pcan_enable: True
fe.pcan_strength: 0.949999988079071
fe.pcan_offset: 80.0
fe.pcan_gain_bits: 21
fe.log_scale_enable: True
fe.log_scale_shift: 6
fe.fft_length: 512
.tflite file size: 21.6kB
Model Profiling Report¶
# Profile on physical EFR32xG24 using MVP accelerator
mltk profile tflite_micro_speech --device --accelerator MVP
Profiling Summary
Name: tflite_micro_speech
Accelerator: MVP
Input Shape: 1x49x40x1
Input Data Type: int8
Output Shape: 1x4
Output Data Type: int8
Flash, Model File Size (bytes): 21.6k
RAM, Runtime Memory Size (bytes): 11.3k
Operation Count: 684.0k
Multiply-Accumulate Count: 336.0k
Layer Count: 4
Unsupported Layer Count: 1
Accelerator Cycle Count: 404.6k
CPU Cycle Count: 115.0k
CPU Utilization (%): 24.2
Clock Rate (hz): 78.0M
Time (s): 6.1m
Ops/s: 112.3M
MACs/s: 55.2M
Inference/s: 164.2
Model Layers
+-------+-----------------+--------+--------+------------+------------+----------+----------------------+--------------+-----------------------------------------+------------+--------------------------------+
| Index | OpCode | # Ops | # MACs | Acc Cycles | CPU Cycles | Time (s) | Input Shape | Output Shape | Options | Supported? | Error Msg |
+-------+-----------------+--------+--------+------------+------------+----------+----------------------+--------------+-----------------------------------------+------------+--------------------------------+
| 0 | conv_2d | 652.0k | 320.0k | 380.5k | 85.7k | 5.4m | 1x49x40x1,8x10x8x1,8 | 1x25x20x8 | Padding:same stride:2x2 activation:relu | True | |
| 1 | reshape | 0 | 0 | 0 | 20.5k | 270.0u | 1x25x20x8,2 | 1x4000 | Type=none | True | |
| 2 | fully_connected | 32.0k | 16.0k | 24.1k | 5.1k | 360.0u | 1x4000,4x4000,4 | 1x4 | Activation:none | False | weights_shape[1] (4000) > 2048 |
| 3 | softmax | 20.0 | 0 | 0 | 3.7k | 60.0u | 1x4 | 1x4 | Type=softmaxoptions | True | |
+-------+-----------------+--------+--------+------------+------------+----------+----------------------+--------------+-----------------------------------------+------------+--------------------------------+
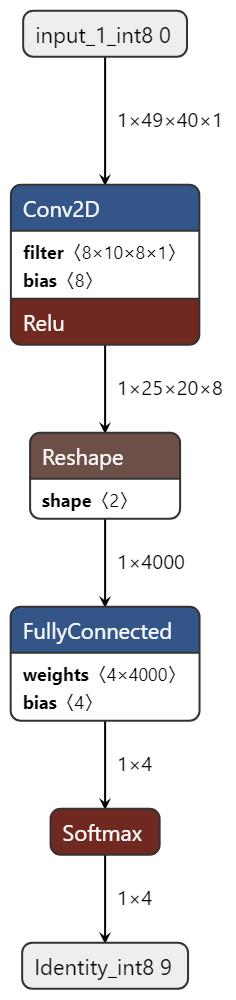
Model Diagram¶
mltk view tflite_micro_speech --tflite
Model Specification¶
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (
InputLayer, Conv2D, Flatten,
Dense, Dropout, BatchNormalization,
Activation
)
from mltk.core.model import (
MltkModel,
TrainMixin,
AudioDatasetMixin,
EvaluateClassifierMixin
)
from mltk.core.preprocess.audio.audio_feature_generator import AudioFeatureGeneratorSettings
from mltk.core.preprocess.audio.parallel_generator import ParallelAudioDataGenerator
from mltk.datasets.audio.speech_commands import speech_commands_v2
# Instantiate the model object with the following 'mixins':
# - TrainMixin - Provides classifier model training operations and settings
# - AudioDatasetMixin - Provides audio data generation operations and settings
# - EvaluateClassifierMixin - Provides classifier evaluation operations and settings
# @mltk_model # NOTE: This tag is required for this model be discoverable
class MyModel(
MltkModel,
TrainMixin,
AudioDatasetMixin,
EvaluateClassifierMixin
):
pass
my_model = MyModel()
#################################################
# General Settings
my_model.version = 1
my_model.description = 'TFLite-Micro speech'
#################################################
# Training Basic Settings
my_model.epochs = -1 # We use the EarlyStopping keras callback to stop the training
my_model.batch_size = 32
my_model.optimizer = 'adam'
my_model.metrics = ['accuracy']
my_model.loss = 'categorical_crossentropy'
#################################################
# Training callback Settings
my_model.checkpoint['monitor'] = 'val_accuracy'
# https://keras.io/api/callbacks/reduce_lr_on_plateau/
# If the test accuracy doesn't improve after 'patience' epochs
# then decrease the learning rate by 'factor'
my_model.reduce_lr_on_plateau = dict(
monitor='accuracy',
factor = 0.25,
patience = 7
)
# https://keras.io/api/callbacks/early_stopping/
# If the validation accuracy doesn't improve after 'patience' epochs then stop training
my_model.early_stopping = dict(
monitor = 'val_accuracy',
patience = 20
)
#################################################
# TF-Lite converter settings
my_model.tflite_converter['optimizations'] = ['DEFAULT']
my_model.tflite_converter['supported_ops'] = ['TFLITE_BUILTINS_INT8']
my_model.tflite_converter['inference_input_type'] = 'int8' # can also be float32
my_model.tflite_converter['inference_output_type'] = 'int8'
# generate a representative dataset from the validation data
my_model.tflite_converter['representative_dataset'] = 'generate'
#################################################
# Audio Data Provider Settings
my_model.dataset = speech_commands_v2
my_model.class_mode = 'categorical'
my_model.classes = ['yes','no','_unknown_','_silence_']
# The numbers of samples for each class is different
# Then ensures each class contributes equally to training the model
my_model.class_weights = 'balanced'
#################################################
# AudioFeatureGenerator Settings
frontend_settings = AudioFeatureGeneratorSettings()
frontend_settings.sample_rate_hz = 16000
frontend_settings.sample_length_ms = 1000
frontend_settings.window_size_ms = 30
frontend_settings.window_step_ms = 20
frontend_settings.filterbank_n_channels = 40
frontend_settings.filterbank_upper_band_limit = 7500
frontend_settings.filterbank_lower_band_limit = 125.0
frontend_settings.noise_reduction_enable = True
frontend_settings.noise_reduction_smoothing_bits = 10
frontend_settings.noise_reduction_even_smoothing = 0.025
frontend_settings.noise_reduction_odd_smoothing = 0.06
frontend_settings.noise_reduction_min_signal_remaining = 0.05
frontend_settings.pcan_enable = True
frontend_settings.pcan_strength = 0.95
frontend_settings.pcan_offset = 80.0
frontend_settings.pcan_gain_bits = 21
frontend_settings.log_scale_enable = True
frontend_settings.log_scale_shift = 6
#################################################
# ParallelAudioDataGenerator Settings
my_model.datagen = ParallelAudioDataGenerator(
dtype=np.int8,
frontend_settings=frontend_settings,
cores=0.35,
debug=False, # Set this to true to enable debugging of the generator
max_batches_pending=16,
validation_split= 0.15,
validation_augmentation_enabled=False,
samplewise_center=False,
samplewise_std_normalization=False,
rescale=None,
unknown_class_percentage=3,
silence_class_percentage=0.2,
offset_range=(0.0,1.0),
trim_threshold_db=20,
noise_colors=None,
# loudness_range=(0.6, 3.0), # In practice, these should be enabled but they will increase training times
# speed_range=(0.6,1.9),
# pitch_range=(0.7,1.4),
# vtlp_range=(0.7,1.4),
bg_noise_range=(0.0,0.3),
bg_noise_dir='_background_noise_'
)
#################################################
# Model Layout
def my_model_builder(model: MyModel):
keras_model = Sequential(name=model.name)
keras_model.add(InputLayer(model.input_shape))
keras_model.add(Conv2D(
filters=8,
kernel_size=(10, 8),
use_bias=True,
padding="same",
strides=(2,2)))
keras_model.add(BatchNormalization())
keras_model.add(Activation('relu'))
keras_model.add(Dropout(
rate=0.5))
keras_model.add(Flatten())
keras_model.add(Dense(
units=model.n_classes,
use_bias=True,
activation='softmax'))
keras_model.compile(
loss=model.loss,
optimizer=model.optimizer,
metrics=model.metrics
)
return keras_model
my_model.build_model_function = my_model_builder
#################################################
# Audio Classifier Settings
#
# These are additional parameters to include in
# the generated .tflite model file.
# The settings are used by the "classify_audio" command
# or audio_classifier example application.
# NOTE: Corresponding command-line options will override these values.
# Controls the smoothing.
# Drop all inference results that are older than <now> minus window_duration
# Longer durations (in milliseconds) will give a higher confidence that the results are correct, but may miss some commands
my_model.model_parameters['average_window_duration_ms'] = 1000
# Minimum averaged model output threshold for a class to be considered detected, 0-255. Higher values increase precision at the cost of recall
my_model.model_parameters['detection_threshold'] = 185
# Amount of milliseconds to wait after a keyword is detected before detecting new keywords
my_model.model_parameters['suppression_ms'] = 750
# The minimum number of inference results to average when calculating the detection value
my_model.model_parameters['minimum_count'] = 3
# Set the volume gain scaler (i.e. amplitude) to apply to the microphone data. If 0 or omitted, no scaler is applied
my_model.model_parameters['volume_gain'] = 2
# This the amount of time in milliseconds an audio loop takes.
my_model.model_parameters['latency_ms'] = 100
# Enable verbose inference results
my_model.model_parameters['verbose_model_output_logs'] = False
##########################################################################################
# The following allows for running this model training script directly, e.g.:
# python tflite_micro_speech.py
#
# Note that this has the same functionality as:
# mltk train tflite_micro_speech
#
if __name__ == '__main__':
import mltk.core as mltk_core
from mltk import cli
# Setup the CLI logger
cli.get_logger(verbose=False)
# If this is true then this will do a "dry run" of the model testing
# If this is false, then the model will be fully trained
test_mode_enabled = True
# Train the model
# This does the same as issuing the command: mltk train tflite_micro_speech-test --clean
train_results = mltk_core.train_model(my_model, clean=True, test=test_mode_enabled)
print(train_results)
# Evaluate the model against the quantized .h5 (i.e. float32) model
# This does the same as issuing the command: mltk evaluate tflite_micro_speech-test
tflite_eval_results = mltk_core.evaluate_model(my_model, verbose=True, test=test_mode_enabled)
print(tflite_eval_results)
# Profile the model in the simulator
# This does the same as issuing the command: mltk profile tflite_micro_speech-test
profiling_results = mltk_core.profile_model(my_model, test=test_mode_enabled)
print(profiling_results)