Unify Attribute Mapper Overview
Introduction
In the UnifySDK, Attribute Mapper is a component that offers a text file based system that allows to define Attribute relations, allowing automatic rules and attribute manipulations using assignments based on text script files.
Attribute Mapper during the Initialization phase, loads the UAM files for the given path and parses the UAM files into AST trees and then evaluates the assignments, and creates dependencies.
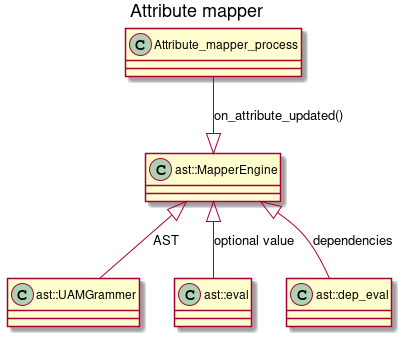
Attribute Mapper Components
| Component | Description |
|---|---|
| Attribute_mapper_process | This component is based on the Contiki process model and helps the mapper in arbitrating when to make calculations based on attribute updates. |
| Attribute_mapper_engine | The purpose of the mapping engine is to define relations between attributes in the attribute store. In general, the relation between the Z-Wave attribute and the Zigbee attributes. |
| Attribute_mapper_grammar | This Components contains the definition of two grammar that is used by the UAM parser. Skipper grammar and Main UAM grammar. |
| Attribute_mapper_parser | This component Parses strings/text into Abstract Syntax Trees using Skipper grammar to exclude white spaces and comments and UAM grammar to parse the mapper logic. |
| Attribute_mapper_ast | This component contains all the data structures which make up the attribute mapping AST. All UAM files are parsed into these structures. |
| Atrribute_mapper evaluators | This component walks through the AST to perform the evaluation of the expressions. There are multiple evaluators in attribute mapper like 1) The attribute path evaluator evaluates a full attribute path and returns the matching attribute store attribute for that attribute path. 2) The attribute dependency evaluator goes through an AST starting with an expression and builds a list of dependencies. |
Attribute Mapper Process
This Contiki process gets the events from the attribute store, like desired or reported attribute updates. This process also checks whether the mapping is paused or allowed and, based on that, processes the update and sends it to the attribute mapper engine. In general, the attribute updates are queued for processing, but attribute Creation and deletion are processed immediately.
Attribute Mapper Engine
The purpose of the mapping engine is to define relations between attributes in the attribute store. In general used to define relations from UCL (which is ZCL based) attributes to stack based attributes and vice versa. The actions performed by the mapping engine are quite similar to the actions performed by a compiler. A compiler parses a text document and builds an Abstract Syntax Tree(AST). The AST is then optimized and the AST nodes are translated into machine opcodes. In the attribute mapper, we are not translating AST nodes to opcodes but instead, we are keeping the AST in memory. The mapping engine only interacts with the attribute store.
The mapping engine uses several C++ classes to perform its tasks.
The ast::UAMGrammar class defines how we translate a text document into our ast using the boost spirit framework.
The ast::dep_eval class is used to build a graph of relations between attributes.
ast::eval class is used to evaluate expressions when a change in an attribute value occurs
When an attribute is updated, the mapper engine gets the destination for the attribute and then gets a list of assignments based on the destination, and run assignments in below order
The highest priority assignment if the destination exists
All of them from low to high priority if the destination does not exist
In Attribute Mapper, the three types of assignments are
Instance assignment, which will verify if an attribute path with a certain value exists
Clearance assignment, which will undefine a value respecting the scope priorities
Regular assignment, which updates the value respecting the scope priorities
Attribute Mapper Parser and Grammer
Main Parser
This parser is only used to parse the UAM files into AST structures. Actual parser logic is defined in attribute_mapper_grammar
Skipper Parser
This parser is used to parse whitespaces and comments.
Main UAM Grammar
This is closely coupled with data types in the AST. This component acts as a grammar definition and does not in itself produce anything.But when used with the boost::qi:parse_phrase function a text document can be transformed into a AST data structure. For details on how this works see: (https://www.boost.org/doc/libs/1_76_0/libs/spirit/doc/html/spirit/qi/tutorials/employee___parsing_into_structs.html)
Rules are used by the main parser. The tokens produced by the parser must be compatible with destination struct Parser operators: (https://www.boost.org/doc/libs/1_80_0/libs/spirit/doc/html/spirit/qi/reference/operator.html)
More details on UAM Grammer are described in How to Write UAM files
Attribute Mapper AST
This component holds all the data structures into which the UAM files are parsed. Few of them are:
ENUMS of operators, Operands and structures of Operations, Expression, and conditions.
Attribute struct holds the Attribute Type and Attribute path
r: reported, d: desired, e: existsAssignment Struct holds the Assignment type along with LHS and RHS
0 - regular, 1 - instance, 2 - clearance assignmentsThey also hold built-in-functions
They also hold the Scope settings, which help to set the Priority and define multiple rules for the same attribute in different priorities.
Attribute Mapper Evaluators
The evaluator walks through the Abstract Syntax Tress. Usually, the evaluator is used to evaluate a top-level expression, but this can also be applied to other AST nodes.
The evaluation is done in a context such that all attribute paths will be evaluated relative to the context (a common parent node in the attribute store). The AST evaluator returns a std::optional because evaluation is not always possible if the needed attribute is not found within the context. If the evaluation context is an invalid attribute all evaluations involving an attribute will return no value.
The AST evaluators are implemented as a functor (a function object). So, it allows us to use the boost::apply_visitor, which can evaluate the boost::variant objects using functors, through the operator() overloading. The use of the boost::apply_visitor is boost::apply_visitor( functor, variant ), this will call the appropriateoperator() overloading for the data type in the variant. See https://www.boost.org/doc/libs/1_76_0/doc/html/boost/apply_visitor.html for further details.
Dependency Evaluator
This evaluator goes through an AST starting with an expression and builds a list of attribute IDs that are used if the expression is to be evaluated. Note that this evaluator accumulates a list of dependencies. i.e. each instance of this class should only be used once. Otherwise, the result will be a combined set of dependencies for each expression this evaluator has been applied on.
Attribute Path Evaluator
This evaluator values a full attribute path and returns the matching attribute store attribute for that attribute path in the context.
Attribute Mapper Path Match Evaluator
Let’s say you have an attribute and a common parent type. If you have to check if your attribute/common parent type could be matching the attribute path of an expression.
For example, a.b[0].c, cheks if these is an attribute of type c, with the parent of type b with value 0, and the grand-parent of type a, and the grand-grand parent of type “common_parent_type”
Attribute Mapper Example
An example of a simple mapping is the relation between the ZigBee attribute OnOff.value and the Z-Wave attribute binary_switch.value, if desired OnOff.value is updated the binary_switch.value should be updated. The same applies to the reported value in the reverse direction.
So in a meta-description, we could describe this behavior with the following:
r’OnOff_Value = r’BinarySwitch_Value
d’BinarySwitch_Value = d’OnOff_Value
This means when the reported value of BinarySwitch_Value changes we would like to update the reported value of OnOff_Value. We will also create the OnOff_Value if it does not exist (this will only happen with reported values). For the desired value we update BinarySwitch_Value if OnOff_Value changes.
The AST of the rule set is stored in memory because when an attribute changes, we should locate dependencies using the AST. The value of each AST node can be calculated in the context of an attribute node. Let’s look at the example where an attribute is updated and the node type of that attribute is a leaf node in the AST. Then we need to try to re-calculate the value of all AST nodes that depends on the updated node. The update may lead to the writing of another attribute. In the example above an update leads to an update of the OnOff value. There could be cases where some node in the AST cannot be evaluated in a given context, for example, if one attribute depends on two other attributes but only one of them is defined. Then the AST will not be fully evaluated in the given context (the node does not support all the required command classes). In this case, the update will not lead to an attribute write.
Example of Multiple Mappings in UAM
Let’s take a fictive example of some ZigBee LED color command class. On the Zigbee side colors are defined as RGBW on the Z-Wave side the color may be in RGBW or may be in just RGB.
A mapping could look like this
zbColorW = zwColor[W] or ((zwColor[R] + zwColor[G] + zwColor[B])*1000 ) / 3333
Here we would pursue the relation using zwColor[W] first if that is not possible we would fall back to ((zwColor[R] + zwColor[G] + zwColor[B])*1000) /3333
AST Helper Components
AST Complexity Counter
Complexity Counter helps in calculating the complexity by counting the number of nodes in the AST.
AST Test Framework
This component helps us to test the rules and run tests for the AST trees.
AST Printer
This component helps to print the operations and path in the AST
AST Cyclic Dependency Checker
This component helps to identify any cyclic dependencies that are formed in the AST tree. Note: At present, this feature is disabled due to incomplete functionality.
AST Reducer
AST evaluator which outputs a copy of the ast in reduced form. AST reducer works by going through the AST and trying to evaluate operands with a normal value evaluator which has an undefined context. This means that the evaluator will only succeed if the operand is a constant, it does not depend on an attribute Note: At present, this feature is disabled due to incomplete functionality.
Example Mapping between Z-Wave and DotDot
To establish a map that reports data on DotDot, we usually need to set reported value of the DotDot attribute to match the reported value or the Z-Wave Attribute.
DotDot attributes, once set, are detected and published automatically on MQTT. This map will for example publish an OnOff attribute for a Binary Switch value.
// Binary switch Command Class
def zwCOMMAND_CLASS_SWITCH_BINARY_VERSION 0x2501
def zwSWITCH_BINARY_STATE 0x2502
def zwSWITCH_BINARY_VALUE 0x2503
// OnOff Cluster
def zbON_OFF_CLUSTER_SWITCH 0x00060000
scope 0 {
// Linking reported attributes zwave -> zigbee
r'zbON_OFF_CLUSTER_SWITCH = r'zwSWITCH_BINARY_STATE.zwSWITCH_BINARY_VALUE
Given that, only the reported is mapped, if an MQTT client tries to set the DotDot OnOff attribute with a command, nothing will happen on the Z-Wave side.
To make Z-Wave value updates based on DotDot commands, the desired value change of a dotdot attribute should be mapped to an update of the desired Z-Wave value:
// Linking desired attributes zigbee -> zwave
d'zwSWITCH_BINARY_STATE.zwSWITCH_BINARY_VALUE = d'zbON_OFF_CLUSTER_SWITCH
Guide for the development of UAM files
Refer How to Write UAM files to get more details abouthow write UAM files and UAM grammar and scope settings.
Further examples of UAM implementation of Command class etc are explained in detail in relater chapter of ZPC Documentation.