|
CMSIS-DSP
Version 1.4.7
CMSIS DSP Software Library
|
|
CMSIS-DSP
Version 1.4.7
CMSIS DSP Software Library
|
Functions | |
| void | arm_conv_f32 (float32_t *pSrcA, uint32_t srcALen, float32_t *pSrcB, uint32_t srcBLen, float32_t *pDst) |
| Convolution of floating-point sequences. | |
| void | arm_conv_fast_opt_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| Convolution of Q15 sequences (fast version) for Cortex-M3 and Cortex-M4. | |
| void | arm_conv_fast_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| Convolution of Q15 sequences (fast version) for Cortex-M3 and Cortex-M4. | |
| void | arm_conv_fast_q31 (q31_t *pSrcA, uint32_t srcALen, q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| Convolution of Q31 sequences (fast version) for Cortex-M3 and Cortex-M4. | |
| void | arm_conv_opt_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| Convolution of Q15 sequences. | |
| void | arm_conv_opt_q7 (q7_t *pSrcA, uint32_t srcALen, q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst, q15_t *pScratch1, q15_t *pScratch2) |
| Convolution of Q7 sequences. | |
| void | arm_conv_q15 (q15_t *pSrcA, uint32_t srcALen, q15_t *pSrcB, uint32_t srcBLen, q15_t *pDst) |
| Convolution of Q15 sequences. | |
| void | arm_conv_q31 (q31_t *pSrcA, uint32_t srcALen, q31_t *pSrcB, uint32_t srcBLen, q31_t *pDst) |
| Convolution of Q31 sequences. | |
| void | arm_conv_q7 (q7_t *pSrcA, uint32_t srcALen, q7_t *pSrcB, uint32_t srcBLen, q7_t *pDst) |
| Convolution of Q7 sequences. | |
Convolution is a mathematical operation that operates on two finite length vectors to generate a finite length output vector. Convolution is similar to correlation and is frequently used in filtering and data analysis. The CMSIS DSP library contains functions for convolving Q7, Q15, Q31, and floating-point data types. The library also provides fast versions of the Q15 and Q31 functions on Cortex-M4 and Cortex-M3.
a[n] and b[n] be sequences of length srcALen and srcBLen samples respectively. Then the convolution
c[n] = a[n] * b[n]
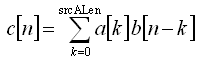
c[n] is of length srcALen + srcBLen - 1 and is defined over the interval n=0, 1, 2, ..., srcALen + srcBLen - 2. pSrcA points to the first input vector of length srcALen and pSrcB points to the second input vector of length srcBLen. The output result is written to pDst and the calling function must allocate srcALen+srcBLen-1 words for the result.a[n] and b[n] are convolved, the signal b[n] slides over a[n]. For each offset n, the overlapping portions of a[n] and b[n] are multiplied and summed together.
a[n] * b[n] = b[n] * a[n].
Fixed-Point Behavior
Fast Versions
Opt Versions
| void arm_conv_f32 | ( | float32_t * | pSrcA, |
| uint32_t | srcALen, | ||
| float32_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| float32_t * | pDst | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
| void arm_conv_fast_opt_q15 | ( | q15_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q15_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q15_t * | pDst, | ||
| q15_t * | pScratch1, | ||
| q15_t * | pScratch2 | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
| [in] | *pScratch1 | points to scratch buffer of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | points to scratch buffer of size min(srcALen, srcBLen). |
Scaling and Overflow Behavior:
arm_conv_q15() for a slower implementation of this function which uses 64-bit accumulation to avoid wrap around distortion. References __SIMD32, _SIMD32_OFFSET, arm_copy_q15(), arm_fill_q15(), srcALen, and srcBLen.
| void arm_conv_fast_q15 | ( | q15_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q15_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q15_t * | pDst | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
Scaling and Overflow Behavior:
arm_conv_q15() for a slower implementation of this function which uses 64-bit accumulation to avoid wrap around distortion. References __SIMD32, _SIMD32_OFFSET, srcALen, and srcBLen.
| void arm_conv_fast_q31 | ( | q31_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q31_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q31_t * | pDst | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
Scaling and Overflow Behavior:
arm_conv_q31() for a slower implementation of this function which uses 64-bit accumulation to provide higher precision. | void arm_conv_opt_q15 | ( | q15_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q15_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q15_t * | pDst, | ||
| q15_t * | pScratch1, | ||
| q15_t * | pScratch2 | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
| [in] | *pScratch1 | points to scratch buffer of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | points to scratch buffer of size min(srcALen, srcBLen). |
Scaling and Overflow Behavior:
arm_conv_fast_q15() for a faster but less precise version of this function for Cortex-M3 and Cortex-M4. References __SIMD32, _SIMD32_OFFSET, arm_copy_q15(), arm_fill_q15(), srcALen, and srcBLen.
| void arm_conv_opt_q7 | ( | q7_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q7_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q7_t * | pDst, | ||
| q15_t * | pScratch1, | ||
| q15_t * | pScratch2 | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
| [in] | *pScratch1 | points to scratch buffer(of type q15_t) of size max(srcALen, srcBLen) + 2*min(srcALen, srcBLen) - 2. |
| [in] | *pScratch2 | points to scratch buffer (of type q15_t) of size min(srcALen, srcBLen). |
Scaling and Overflow Behavior:
max(srcALen, srcBLen)<131072. The 18.14 result is then truncated to 18.7 format by discarding the low 7 bits and then saturated to 1.7 format. References __PACKq7, __SIMD32, _SIMD32_OFFSET, arm_fill_q15(), srcALen, and srcBLen.
| void arm_conv_q15 | ( | q15_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q15_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q15_t * | pDst | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
Scaling and Overflow Behavior:
arm_conv_fast_q15() for a faster but less precise version of this function for Cortex-M3 and Cortex-M4.arm_conv_opt_q15() for a faster implementation of this function using scratch buffers. References __SIMD32, _SIMD32_OFFSET, srcALen, and srcBLen.
| void arm_conv_q31 | ( | q31_t * | pSrcA, |
| uint32_t | srcALen, | ||
| q31_t * | pSrcB, | ||
| uint32_t | srcBLen, | ||
| q31_t * | pDst | ||
| ) |
| [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
Scaling and Overflow Behavior:
arm_conv_fast_q31() for a faster but less precise implementation of this function for Cortex-M3 and Cortex-M4. | [in] | *pSrcA | points to the first input sequence. |
| [in] | srcALen | length of the first input sequence. |
| [in] | *pSrcB | points to the second input sequence. |
| [in] | srcBLen | length of the second input sequence. |
| [out] | *pDst | points to the location where the output result is written. Length srcALen+srcBLen-1. |
Scaling and Overflow Behavior:
max(srcALen, srcBLen)<131072. The 18.14 result is then truncated to 18.7 format by discarding the low 7 bits and then saturated to 1.7 format.arm_conv_opt_q7() for a faster implementation of this function. 
